Miesięczne wydatki na odbitki kserograficzne (dane w zł) ogółu studentów SGH mają rozkład
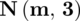 . Badanie 5 losowo wybranych studentów ze względu na wydatki na odbitki dostarczyło następujących danych: 10; 12; 8; 15; 10. Ilu co najmniej studentów należy wylosować do próby, aby przy poziomie ufności 0,95 oszacować średnie wydatki ogółu studentów, otrzymując przedział o długości nieprzekraczającej 4 zł?
. Badanie 5 losowo wybranych studentów ze względu na wydatki na odbitki dostarczyło następujących danych: 10; 12; 8; 15; 10. Ilu co najmniej studentów należy wylosować do próby, aby przy poziomie ufności 0,95 oszacować średnie wydatki ogółu studentów, otrzymując przedział o długości nieprzekraczającej 4 zł?
1. JAK ROZPOZNAĆ ZADANIE DOTYCZĄCE MINIMALNEJ LICZEBNOŚCI PRÓBY?
Po przeczytaniu całego zadania zwracamy uwagę na zdanie:
“ Ilu co najmniej studentów należy wylosować do próby, aby przy poziomie ufności 0,95 oszacować średnie wydatki ogółu studentów, otrzymując przedział o długości nieprzekraczającej 4 zł? ”
Na początku może się wydawać, że zadanie dotyczy estymacji przedziałowej, ponieważ pojawia się zwrot: otrzymując przedział o długości ... . Niemniej jednak przewagę nad tym wyrażeniem zawsze ma: ilu co najmniej studentów należy wylosować do próby .... , czyli szukamy minimalnej liczebności próby. Nie ma również ani słowa o maksymalnym błędzie szacunku, ale jest on ukryty w zadaniu pod innym szyldem. Nie jest to nic nadzwyczajnego, ponieważ zagadnienie minimalnej liczebności próby ściśle wiąże się z estymacją przedziałową. Pojawia się również wyrażenie poziom ufności .. Biorąc to pod uwagę mamy na pewno do czynienia z zadaniem dotyczącym minimalnej liczebności próby.
2. ANALIZA I PRAWIDŁOWE WYPISANIE DANYCH.
Czytamy zdanie po zdaniu.
“
Miesięczne wydatki na odbitki kserograficzne (dane w zł) ogółu studentów SGH mają rozkład
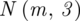 .
”
.
”
Symbol
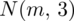 oznacza, że miesięczne wydatki na odbitki charakteryzują się rozkładem normalnym o nieznanej średniej
oznacza, że miesięczne wydatki na odbitki charakteryzują się rozkładem normalnym o nieznanej średniej
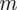 i znanym odchyleniu standardowym
i znanym odchyleniu standardowym
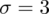 . Zapis ten zawsze odnosi się do populacji (wcześniej wspominałam w części teoretycznej, że próba jest z reguły za mała aby stwierdzić rozkład normalny).
. Zapis ten zawsze odnosi się do populacji (wcześniej wspominałam w części teoretycznej, że próba jest z reguły za mała aby stwierdzić rozkład normalny).
Badanie 5 losowo wybranych studentów ze względu na wydatki na odbitki dostarczyło następujących danych: 10; 12; 8; 15; 10.
Dowiadujemy się , że wylosowano 5 osób - jest to liczebność próby, którą zapiszemy
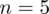 . Podano również wyniki z próby - liczby wypisane po przecinku tzw. dane indywidualne. Jeżeli takowe posiadamy, to zawsze w razie potrzeby można z nich obliczyć średnią
. Podano również wyniki z próby - liczby wypisane po przecinku tzw. dane indywidualne. Jeżeli takowe posiadamy, to zawsze w razie potrzeby można z nich obliczyć średnią
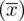 , wariancję
, wariancję
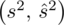 lub odchylenie standardowe
lub odchylenie standardowe
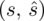 . Nie liczmy jednak tych parametrów od razu, ponieważ może się okazać, że wcale nie będą nam potrzebne.
. Nie liczmy jednak tych parametrów od razu, ponieważ może się okazać, że wcale nie będą nam potrzebne.
“ Ilu co najmniej studentów należy wylosować do próby, aby przy poziomie ufności 0,95 oszacować średnie wydatki ogółu studentów, otrzymując przedział o długości nieprzekraczającej 4 zł? ”
Szukamy liczebności próby (liczba studentów), którą oznaczamy literą
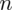 . I tu pojawia się wątpliwość - przecież przed chwilą wypisaliśmy liczebność próby
. I tu pojawia się wątpliwość - przecież przed chwilą wypisaliśmy liczebność próby
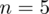 , więc po co szukać czegoś co już jest znane? Prawdopodobnie jest to próba wstępna (pilotażowa) lub też autor zadania chce nas sprowadzić na manowce :). Na razie oznaczmy tymczasowo liczebność naszej próby symbolem
, więc po co szukać czegoś co już jest znane? Prawdopodobnie jest to próba wstępna (pilotażowa) lub też autor zadania chce nas sprowadzić na manowce :). Na razie oznaczmy tymczasowo liczebność naszej próby symbolem
 (próba pilotażowa). Wszystko się okaże na etapie wyboru wzoru.
(próba pilotażowa). Wszystko się okaże na etapie wyboru wzoru.
Podano również poziom ufności, a więc
 . Od razu wyznaczamy
. Od razu wyznaczamy
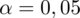 .
.
Jak pamiętamy, w zadaniach dotyczących minimalnej liczebności próby ważnym elementem jest wartość maksymalnego błędu szacunku
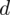 . Zamiast tego dowiadujemy się, że przedział ufności powinien mieć długość nieprzekraczającą 4 zł. Warto zapamiętać, że maksymalny błąd szacunku to połowa przedziału ufności. Jeśli informacja ta wydaje się być zbyt lakoniczna, odsyłam do szerszego wytłumaczenia
http://matma-po-ludzku.pl/statystyka/wnioskowanie/estymacja/estymacja_sredniej/zadanie29.php
. Otrzymujemy zatem
. Zamiast tego dowiadujemy się, że przedział ufności powinien mieć długość nieprzekraczającą 4 zł. Warto zapamiętać, że maksymalny błąd szacunku to połowa przedziału ufności. Jeśli informacja ta wydaje się być zbyt lakoniczna, odsyłam do szerszego wytłumaczenia
http://matma-po-ludzku.pl/statystyka/wnioskowanie/estymacja/estymacja_sredniej/zadanie29.php
. Otrzymujemy zatem
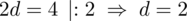 .
.
Podsumowując tworzymy przejrzystą tabelę z danymi:
|
POPULACJA
studenci
|
PRÓBA
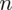 wybranych studentów
wybranych studentów
|
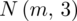 - rozkład normalny o nieznanej średniej
- rozkład normalny o nieznanej średniej
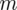 i znanym odchyleniu standardowym
i znanym odchyleniu standardowym
|
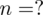
 - próba pilotażowa
- próba pilotażowa
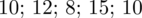 - dane indywidualne (można obliczyć średnią
- dane indywidualne (można obliczyć średnią
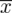 , wariancję
, wariancję
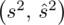 , odchylenie standardowe
, odchylenie standardowe
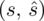 )
)
|

 - współczynnik ufności,
- współczynnik ufności,
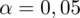
3. WYBÓR ODPOWIEDNIEGO WZORU.
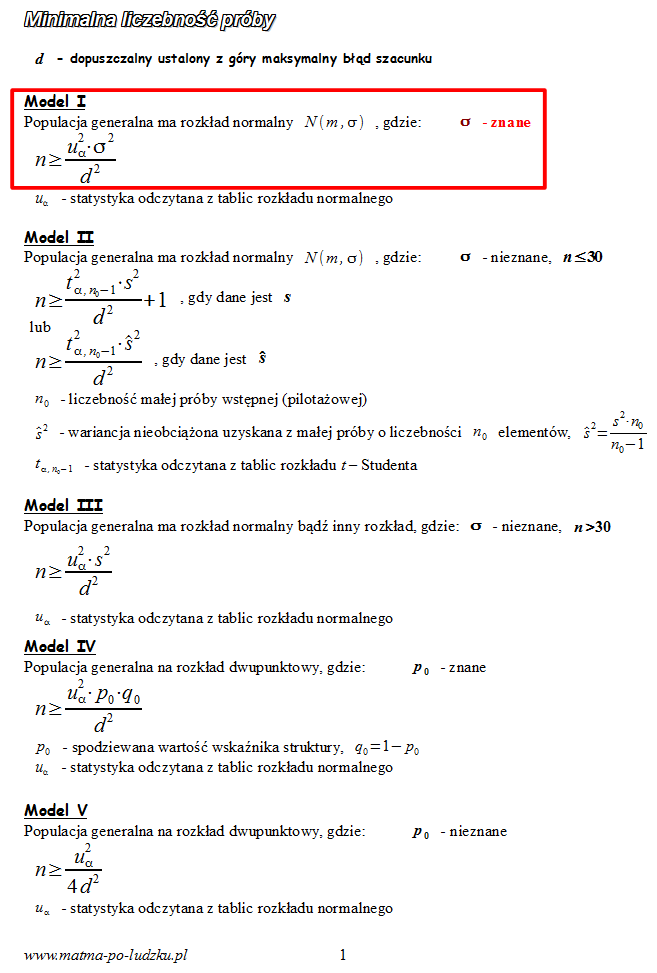
Spójrzmy w kartę wzorów. Dla minimalnej liczebności próby mamy do wyboru pięć modeli. Teraz wracamy do danych i na początku sprawdzamy, czy
 jest znana. Stwierdzamy, że
jest znana. Stwierdzamy, że
 jest znana
jest znana
 , zatem wybieramy
model I
. Jednak może się tu pojawić wątpliwość co do wybranej formuły, ponieważ dysponujemy liczebnością próby pilotażowej
, zatem wybieramy
model I
. Jednak może się tu pojawić wątpliwość co do wybranej formuły, ponieważ dysponujemy liczebnością próby pilotażowej
 i wynikami z tejże próbki, które pozwalają na obliczenie
i wynikami z tejże próbki, które pozwalają na obliczenie
 . Próba pilotażowa wskazuje na model II, ale jeżeli
. Próba pilotażowa wskazuje na model II, ale jeżeli
 jest znana, to wybiera się zawsze model I. Wynika to z faktu, że
jest znana, to wybiera się zawsze model I. Wynika to z faktu, że
 dotyczy populacji, a
dotyczy populacji, a
 próby, która może istotnie różnić się od całej populacji. Podsumowując - dane dotyczące populacji mają większą wagę niż dane z prób, które wcale nie muszą być reprezentatywne. Tak więc to była podpucha ze strony autora.
próby, która może istotnie różnić się od całej populacji. Podsumowując - dane dotyczące populacji mają większą wagę niż dane z prób, które wcale nie muszą być reprezentatywne. Tak więc to była podpucha ze strony autora.
4. UZUPEŁNIANIE WYBRANEGO WZORU I OBLICZENIA.
Wracamy do danych z tabeli i uzupełniamy wzór
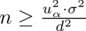 konkretnymi liczbami.
konkretnymi liczbami.
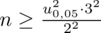
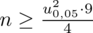
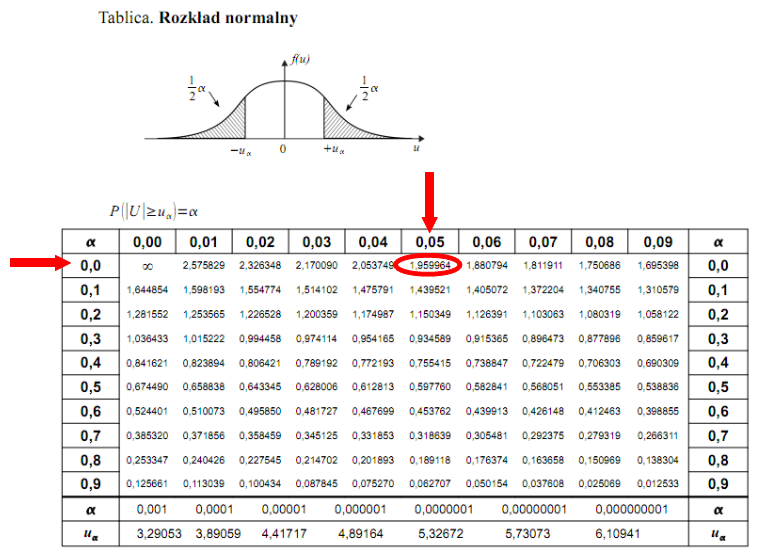
Teraz należy odczytać odpowiednią statystykę z tablic. W formule znajduje się literka
u
, zatem skorzystamy z tablic rozkładu normalnego:
http://matma-po-ludzku.pl/materialy/statystyka/wzory/rnormalny.pdf
. Zapis
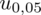 oznacza konieczność odnalezienia statystyki dla
oznacza konieczność odnalezienia statystyki dla
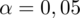 . Czytanie z tablic rozkładu normalnego nie jest trudne. Sumuje się wartości znajdujące się na obrzeżach tzn. z kolumny, która stanowi części dziesiętne i z wiersza, który traktujemy jako części setne. W przypadku
. Czytanie z tablic rozkładu normalnego nie jest trudne. Sumuje się wartości znajdujące się na obrzeżach tzn. z kolumny, która stanowi części dziesiętne i z wiersza, który traktujemy jako części setne. W przypadku
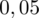 sumujemy
sumujemy
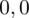 i
i
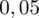 czyli
czyli
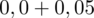 .
.
Wracamy do obliczeń i podstawiamy
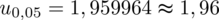 (zaokrąglanie to indywidualna sprawa wynikająca najczęściej z preferencji prowadzącego):
(zaokrąglanie to indywidualna sprawa wynikająca najczęściej z preferencji prowadzącego):
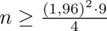
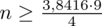
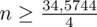
5. WYNIK I INTERPRETACJA.
Ostatecznie otrzymujemy:
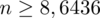 , czyli ZAWSZE zaokrąglając w górę otrzymujemy
, czyli ZAWSZE zaokrąglając w górę otrzymujemy
 .
.
Interpretacja brzmi następująco: Z ufnością 0,95 dla oszacowania średniego poziomu wydatków ogółu studentów, do próby należy wylosować 9 żaków.