Postanowiono zbadać, jaki odsetek gabinetów stomatologicznych funkcjonuje na wsi. Badanie wstępne wykazało, że jest ich około 10%. Ile gabinetów należy wylosować, by oszacować odsetek gabinetów stomatologicznych funkcjonujących na wsi z dokładnością do 2% przy
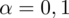 ?
?
a) 609 b)1691 c) 370 d) 864 e) inna liczebność, jaka? …..
1. JAK ROZPOZNAĆ ZADANIE DOTYCZĄCE MINIMALNEJ LICZEBNOŚCI PRÓBY?
Po przeczytaniu całego zadania zwracamy uwagę na zdanie:
“
Ile gabinetów należy wylosować, by oszacować odsetek gabinetów stomatologicznych funkcjonujących na wsi z dokładnością do 2% przy
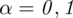 ?
”
?
”
Występują tu zwroty:
ile gabinetów należy wylosować ...
,
z dokładnością.
Co prawda nie podano
współczynnika ufności, ale jest już gotowa
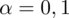 . Biorąc pod uwagę wszystkie słowa-klucze mamy na pewno do czynienia z zadaniem dotyczącym minimalnej liczebności próby.
. Biorąc pod uwagę wszystkie słowa-klucze mamy na pewno do czynienia z zadaniem dotyczącym minimalnej liczebności próby.
2. ANALIZA I PRAWIDŁOWE WYPISANIE DANYCH.
Czytamy zdanie po zdaniu.
Postanowiono zbadać, jaki odsetek gabinetów stomatologicznych funkcjonuje na wsi.
W tym zdaniu nie ma danych liczbowych, więc je pomijamy.
Badanie wstępne wykazało, że jest ich około 10%.
Dowiadujemy się, że 10% gabinetów funkcjonuje na wsi. Jest to procent ogółu gabinetów z badania wstępnego, a więc wskaźnik struktury w populacji. Opisujemy go symbolem
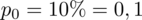 .
.
“
Ile gabinetów należy wylosować, by oszacować odsetek gabinetów stomatologicznych funkcjonujących na wsi z dokładnością do 2% przy
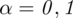 ?
”
?
”
Szukamy liczebności próby gabinetów, którą oznaczamy literą
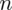 . Dokładność oszacowania czyli maksymalny błąd szacunku wynosi
. Dokładność oszacowania czyli maksymalny błąd szacunku wynosi
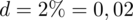 . Podano również gotowe
. Podano również gotowe
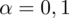 .
.
Podsumowując tworzymy przejrzystą tabelę z danymi:
|
POPULACJA
gabinety stomatologiczne
|
PRÓBA
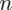 wybranych gabinetów
wybranych gabinetów
|
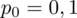
|
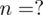
|
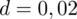
3. WYBÓR ODPOWIEDNIEGO WZORU.
Spójrzmy w kartę wzorów. Dla minimalnej liczebności próby mamy do wyboru pięć modeli. Teraz wracamy do danych i na początku sprawdzamy, czy
 jest znana. Stwierdzamy, że
jest znana. Stwierdzamy, że
 nie jest znana
, zatem wykluczamy model I.
Nie mamy próby pilotażowej o konkretnej liczebności
, gdzie możliwe jest wyliczenie wariancji
nie jest znana
, zatem wykluczamy model I.
Nie mamy próby pilotażowej o konkretnej liczebności
, gdzie możliwe jest wyliczenie wariancji
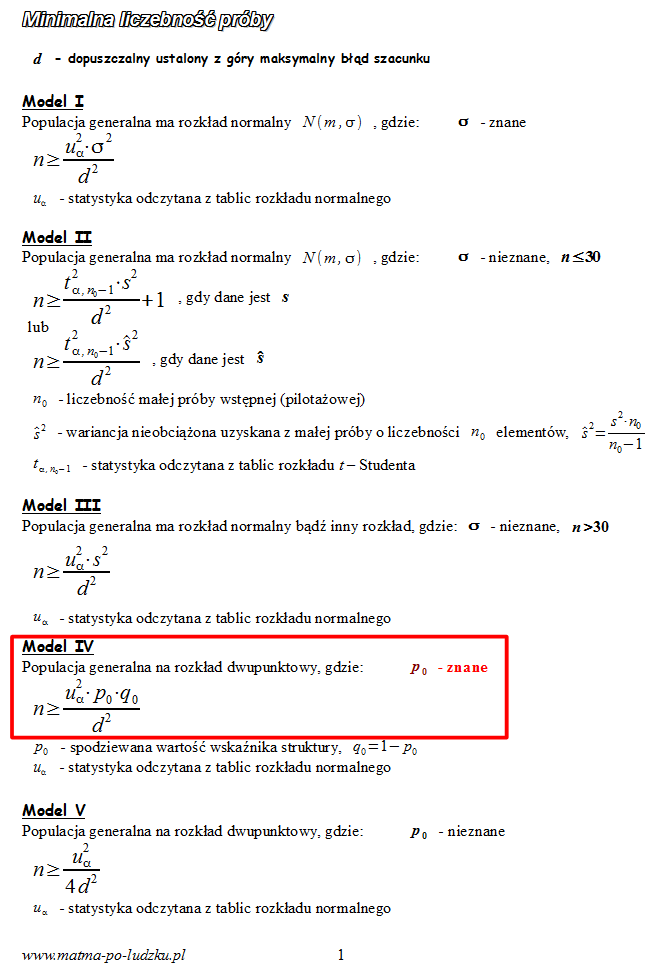
 , wobec tego odrzucamy również modele II i III. W zamian dysponujemy
spodziewanym wskaźnikiem struktury
, wobec tego odrzucamy również modele II i III. W zamian dysponujemy
spodziewanym wskaźnikiem struktury
 , zatem wybieramy
model IV
.
, zatem wybieramy
model IV
.
4. UZUPEŁNIANIE WYBRANEGO WZORU I OBLICZENIA.
Wracamy do danych z tabeli i uzupełniamy wzór
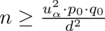 konkretnymi liczbami. Zgodnie ze wzorem
konkretnymi liczbami. Zgodnie ze wzorem
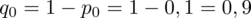 .
.
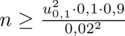
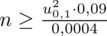
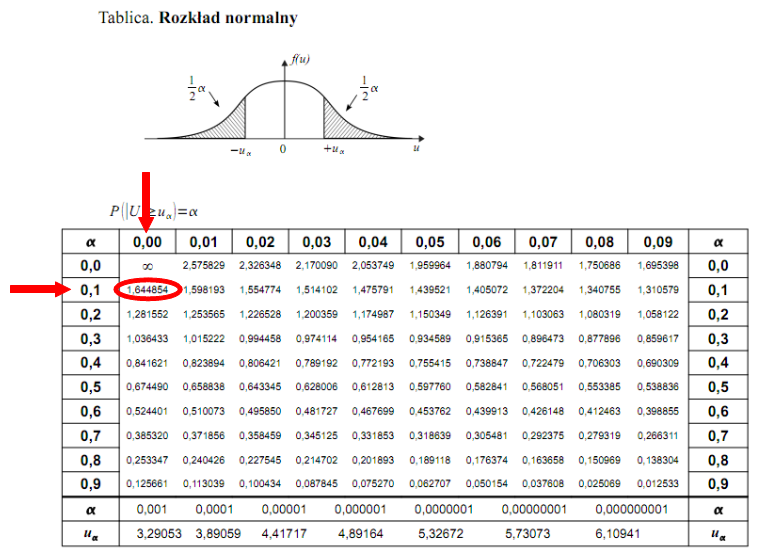
Teraz należy odczytać odpowiednią statystykę z tablic. W formule znajduje się literka
u
, zatem skorzystamy z tablic rozkładu normalnego:
http://matma-po-ludzku.pl/materialy/statystyka/wzory/rnormalny.pdf
. Zapis
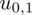 oznacza konieczność odnalezienia statystyki dla
oznacza konieczność odnalezienia statystyki dla
 . Czytanie z tablic rozkładu normalnego nie jest trudne. Sumuje się wartości znajdujące się na obrzeżach tzn. z kolumny, która stanowi części dziesiętne i z wiersza, który traktujemy jako części setne. W przypadku
. Czytanie z tablic rozkładu normalnego nie jest trudne. Sumuje się wartości znajdujące się na obrzeżach tzn. z kolumny, która stanowi części dziesiętne i z wiersza, który traktujemy jako części setne. W przypadku
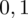 sumujemy
sumujemy
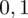 i
i
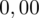 czyli
czyli
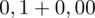 .
.
Wracamy do obliczeń i podstawiamy
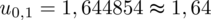 (zaokrąglanie to indywidualna sprawa wynikająca najczęściej z preferencji prowadzącego):
(zaokrąglanie to indywidualna sprawa wynikająca najczęściej z preferencji prowadzącego):
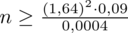
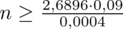
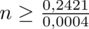
5. WYNIK I INTERPRETACJA.
Ostatecznie otrzymujemy:
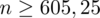 , czyli ZAWSZE zaokrąglając w górę otrzymujemy
, czyli ZAWSZE zaokrąglając w górę otrzymujemy
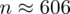 .
.
Interpretacja brzmi następująco: Aby oszacować odsetek gabinetów stomatologicznych funkcjonujących na wsi z ufnością 0,9 należy wylosować do próby 606 gabinetów. Wybieramy zatem odpowiedź A, różnica między rezultatami wynika z zaokrąglonej wartości odczytanej z tablic, tak jak już wcześniej wspomniałam reguły zaokrąglania zależą od wykładowcy :).