Dyrekcja dużego domu towarowego zamierza ustalić, ile czasu spędzają w nim klienci w soboty. W tym celu wylosowano próbę pilotażową, która dała następujące wyniki:
Przyjmując współczynnik ufności 0,96 oraz maksymalny błąd szacunku nieprzekraczający 0,5 minuty, oszacuj, czy wylosowana próba wstępna jest wystarczająca do oszacowania średniego czasu w populacji generalnej klientów.
1. JAK ROZPOZNAĆ ZADANIE DOTYCZĄCE MINIMALNEJ LICZEBNOŚCI PRÓBY?
Po przeczytaniu całego zadania zwracamy uwagę na zdanie:
“ Przyjmując współczynnik ufności 0,96 oraz maksymalny błąd szacunku nieprzekraczający 0,5 minuty, oszacuj, czy wylosowana próba wstępna jest wystarczająca do oszacowania średniego czasu w populacji generalnej klientów. ”
Występują tu zwroty: maksymalny błąd szacunku ... , czy wylosowana próba wstępna jest wystarczająca ... . Odnajdujemy również wyrażenie: współczynnik ufności . Biorąc pod uwagę wszystkie słowa-klucze mamy na pewno do czynienia z zadaniem dotyczącym minimalnej liczebności próby.
2. ANALIZA I PRAWIDŁOWE WYPISANIE DANYCH.
Czytamy zdanie po zdaniu.
Dyrekcja dużego domu towarowego zamierza ustalić, ile czasu spędzają w nim klienci w soboty. W tym celu wylosowano próbę pilotażową, która dała następujące wyniki:
Z podanej tabeli wynika, że wylosowano
 klientów do próby pilotażowej. Wydaje się dziwne, że w zadaniu, którego istotą jest znalezienie liczebności próby podaje się właśnie to, czego szukamy - a więc liczebność próby. Nie ma powodu do niepokoju - jest to liczebność próby wstępnej (jak podano w zadaniu), którą oznaczamy
klientów do próby pilotażowej. Wydaje się dziwne, że w zadaniu, którego istotą jest znalezienie liczebności próby podaje się właśnie to, czego szukamy - a więc liczebność próby. Nie ma powodu do niepokoju - jest to liczebność próby wstępnej (jak podano w zadaniu), którą oznaczamy
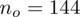 . Podano również informacje o konkretnych wynikach z próby. Jeżeli dysponujemy wartościami tabelarycznymi, to zawsze możemy policzyć średnią
. Podano również informacje o konkretnych wynikach z próby. Jeżeli dysponujemy wartościami tabelarycznymi, to zawsze możemy policzyć średnią
 , wariancję
, wariancję
 i odchylenie standardowe
i odchylenie standardowe
 (lub
(lub
 ,
,
 ). Nie liczmy jednak tych parametrów od razu, ponieważ dopiero etap wyboru formuły wskaże nam czego potrzebujemy. Po prostu chodzi o to, żeby nie liczyć na zapas np. odchylenia, bo może okazać się niepotrzebne w późniejszych obliczeniach.
). Nie liczmy jednak tych parametrów od razu, ponieważ dopiero etap wyboru formuły wskaże nam czego potrzebujemy. Po prostu chodzi o to, żeby nie liczyć na zapas np. odchylenia, bo może okazać się niepotrzebne w późniejszych obliczeniach.
“ Przyjmując współczynnik ufności 0,96 oraz maksymalny błąd szacunku nieprzekraczający 0,5 minuty, oszacuj, czy wylosowana próba wstępna jest wystarczająca do oszacowania średniego czasu w populacji generalnej klientów. ”
Podano współczynnik ufności, a więc
 . Od razu wyznaczamy
. Od razu wyznaczamy
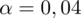 . Maksymalny błąd szacunku wynosi
. Maksymalny błąd szacunku wynosi
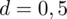 minuty. Szukamy liczebności próby właściwej, którą oznaczamy literą
minuty. Szukamy liczebności próby właściwej, którą oznaczamy literą
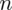 .
.
Podsumowując tworzymy przejrzystą tabelę z danymi:
|
POPULACJA
klienci domu towarowego
|
PRÓBA
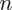 wybranych klientów
wybranych klientów
|
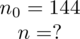 tabela z danymi (można obliczyć średnią
tabela z danymi (można obliczyć średnią
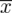 , wariancję
, wariancję

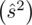 , odchylenie standardowe
, odchylenie standardowe

 )
)
|
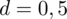
 - współczynnik ufności,
- współczynnik ufności,
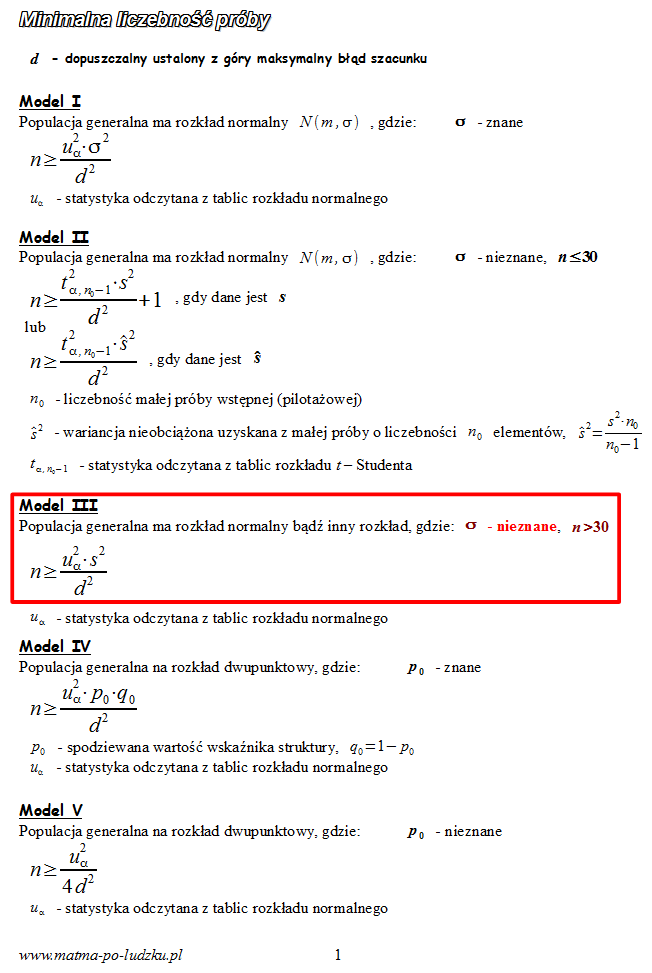
3. WYBÓR ODPOWIEDNIEGO WZORU.
Spójrzmy w kartę wzorów. Dla minimalnej liczebności próby mamy do wyboru pięć modeli. Teraz wracamy do danych i na początku sprawdzamy, czy
 jest znana. Stwierdzamy, że
jest znana. Stwierdzamy, że
 nie jest znana
, zatem wykluczamy model I. Ponadto wiemy, że mamy do czynienia z próbą pilotażową, której liczebność jest większa niż 30 (
nie jest znana
, zatem wykluczamy model I. Ponadto wiemy, że mamy do czynienia z próbą pilotażową, której liczebność jest większa niż 30 (
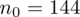 ) i istnieje możliwość wyliczenia
) i istnieje możliwość wyliczenia
 z próby wstępnej na podstawie tabeli z danymi- wobec tego wybieramy
model III
.
z próby wstępnej na podstawie tabeli z danymi- wobec tego wybieramy
model III
.
4. UZUPEŁNIANIE WYBRANEGO WZORU I OBLICZENIA.
Wracamy do danych z tabeli i uzupełniamy wzór
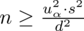 konkretnymi liczbami. Jak widać brakuje tylko
konkretnymi liczbami. Jak widać brakuje tylko
 , więc dopóki nie znajdziemy wartości tego parametru nie możemy obliczyć liczebności próby właściwej. Wyliczanie wariancji z próby jest zagadnieniem ze statystki opisowej.
, więc dopóki nie znajdziemy wartości tego parametru nie możemy obliczyć liczebności próby właściwej. Wyliczanie wariancji z próby jest zagadnieniem ze statystki opisowej.
Dysponujemy danymi tabelarycznymi, gdzie warianty cechy (czas w minutach) są w formie przedziałów tzn. od jednej wartości do drugiej wartości. Taki szereg określa się szeregiem rozdzielczym przedziałowym. Przeredagujmy zatem tabelę z zadania właśnie na tą postać szeregu.
 - warianty obserwacji (czas w minutach)
- warianty obserwacji (czas w minutach)
|
 - liczebności poszczególnych przedziałów klasowych (liczba klientów)
- liczebności poszczególnych przedziałów klasowych (liczba klientów)
|

|
|

|

|

|
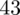
|

|

|
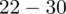
|
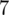
|
 (suma)
(suma)
|
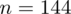
|
W przypadku szeregu rozdzielczego przedziałowego nie ma możliwości pomyłki do tego, co jest wariantem cechy, a co liczebnością
 , ponieważ nie zdarza się, aby
, ponieważ nie zdarza się, aby
 było zapisane w formie przedziałów. Symbol
było zapisane w formie przedziałów. Symbol
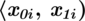 to po prostu ogólny zapis przedziału lewostronnie domkniętego i prawostronnie otwartego (chyba najczęściej używany – chociaż zależy od preferencji prowadzącego). Należy pilnować, aby końcówka każdego przedziału była początkiem następnego. W tabeli z zadania mamy właśnie przedstawioną sytuację
to po prostu ogólny zapis przedziału lewostronnie domkniętego i prawostronnie otwartego (chyba najczęściej używany – chociaż zależy od preferencji prowadzącego). Należy pilnować, aby końcówka każdego przedziału była początkiem następnego. W tabeli z zadania mamy właśnie przedstawioną sytuację
 ,
,
 (kończymy przedział na 6, następny również zaczynamy od 6), itd. w związku z tym nie musimy nic zmieniać, zachowana jest ciągłość.
(kończymy przedział na 6, następny również zaczynamy od 6), itd. w związku z tym nie musimy nic zmieniać, zachowana jest ciągłość.
Wzór na wariancję z danych szeregu przedziałowego wygląda następująco:
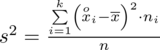 . Jest też alternatywa
. Jest też alternatywa
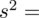
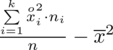 , ale będziemy używać pierwszej wersji. Okazuje się, że do policzenia wariancji i tak niezbędna jest średnia.
, ale będziemy używać pierwszej wersji. Okazuje się, że do policzenia wariancji i tak niezbędna jest średnia.
W szeregu przedziałowym średnią liczymy ze wzoru
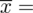
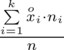 . Na początku wyjaśnijmy symbol
. Na początku wyjaśnijmy symbol
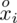 . Oznacza on środek każdego z podanych przedziałów, a obliczany jest na podstawie formuły
. Oznacza on środek każdego z podanych przedziałów, a obliczany jest na podstawie formuły
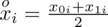 . Upraszczając, należy zsumować początek i koniec każdego przedziału i wynik podzielić na dwa. Wracamy do wzoru na średnią. Znak
. Upraszczając, należy zsumować początek i koniec każdego przedziału i wynik podzielić na dwa. Wracamy do wzoru na średnią. Znak
 oznacza sumę. Pod tym symbolem znajduje się zapis
oznacza sumę. Pod tym symbolem znajduje się zapis
 , a nad nim
, a nad nim
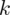 ,
,
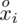 to środki kolejnych przedziałów , a
to środki kolejnych przedziałów , a
 liczebności dla kolejnych przedziałów. Wszystko razem oznacza, że będziemy sumować kolejne iloczyny
liczebności dla kolejnych przedziałów. Wszystko razem oznacza, że będziemy sumować kolejne iloczyny
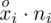 , gdzie
, gdzie
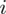 będzie rosło od
będzie rosło od
 aż do wartości
aż do wartości
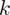 , czyli
, czyli
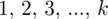 , a więc ogólnie:
, a więc ogólnie:
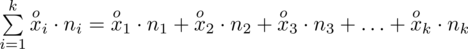
W naszym przypadku
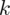 znad znaku sumy oznacza liczbę przedziałów klasowych (ilość wierszy w tabeli z danymi). Tak więc średnia będzie miała uproszczony wzór:
znad znaku sumy oznacza liczbę przedziałów klasowych (ilość wierszy w tabeli z danymi). Tak więc średnia będzie miała uproszczony wzór:
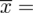
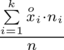 =
=
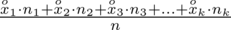
Czym jest
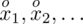 ,
,
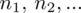 oraz
oraz
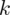 ? Wszystko to zostanie pokazane dokładnie w tabeli. Obliczmy w niej również środki poszczególnych przedziałów.
? Wszystko to zostanie pokazane dokładnie w tabeli. Obliczmy w niej również środki poszczególnych przedziałów.
|
Numer klasy
|
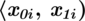 - czas w minutach
- czas w minutach
|
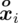 - środki przedziałów
- środki przedziałów
|
 - liczba klientów
- liczba klientów
|
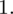
|

|
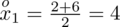
|

|

|

|
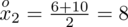
|

|

|

|
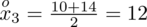
|

|

|

|
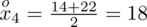
|

|
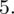
|
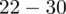
|
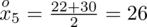
|
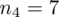
|
 klas
klas
|
 (suma)
(suma)
|
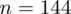
|
Uzupełniając wzór średniej dla
 otrzymujemy:
otrzymujemy:
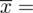
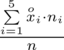 =
=
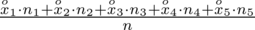 i oczywiście możemy uzupełnić go danymi z tabeli, ale proponuję nadal korzystać z tabeli i wykonywać w niej obliczenia. Po pierwsze jest bardziej klarowna, po drugie ułamek powstały po rozpisaniu wzoru może okazać się dłuższy niż w tym konkretnym zadaniu i łatwo tu o pomyłkę. W tabelce powoli budujemy wzór na średnią z szeregu przedziałowego, a jej nagłówki zawsze wyglądają tak samo. Każdą wartość
i oczywiście możemy uzupełnić go danymi z tabeli, ale proponuję nadal korzystać z tabeli i wykonywać w niej obliczenia. Po pierwsze jest bardziej klarowna, po drugie ułamek powstały po rozpisaniu wzoru może okazać się dłuższy niż w tym konkretnym zadaniu i łatwo tu o pomyłkę. W tabelce powoli budujemy wzór na średnią z szeregu przedziałowego, a jej nagłówki zawsze wyglądają tak samo. Każdą wartość
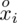 mnożymy przez odpowiadającą jej wartość
mnożymy przez odpowiadającą jej wartość
 , a następnie sumujemy powstałe iloczyny. Przecięcie wiersza z symbolem
, a następnie sumujemy powstałe iloczyny. Przecięcie wiersza z symbolem
 i kolumny
i kolumny
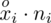 daje kompletny licznik wzoru na średnią.
daje kompletny licznik wzoru na średnią.
|
Numer klasy
|
 - środki przedziałów
- środki przedziałów
|
 - liczba klientów
- liczba klientów
|
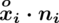
|
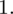
|

|

|
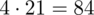
|

|

|

|
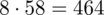
|

|

|

|
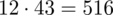
|

|

|

|
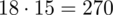
|
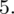
|

|
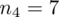
|
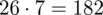
|

|
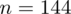
|
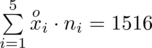
|
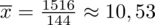
Dysponujemy wartością średniej, zatem możemy wrócić do obliczania wariancji. Rozpiszemy wzór analogicznie jak w przypadku średniej. Najpierw ogólnie:

i dla
 :
:
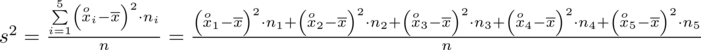
Tu też można podstawiać dane z tabeli, ale ponownie proponuję trzymać się obliczeń tabelarycznych. Można kontynuować poprzednią tabelę dopisując kolejne kolumny. Znowu krok po kroku będziemy tworzyć licznik ze wzoru. Dopisana pierwsza kolumna - od każdego środka przedziału
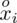 odejmujemy wcześniej wyliczoną średnią
odejmujemy wcześniej wyliczoną średnią
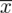 , druga kolumna to podniesienie wyników z poprzedniej do kwadratu. Ostatnia to wymnożenie wyników z drugiej przez odpowiadające im wartości
, druga kolumna to podniesienie wyników z poprzedniej do kwadratu. Ostatnia to wymnożenie wyników z drugiej przez odpowiadające im wartości
 i dopiero ona jest sumowana (przecięcie wiersza z symbolem
i dopiero ona jest sumowana (przecięcie wiersza z symbolem
 i
i
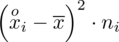 daje kompletny licznik wzoru na wariancję).
daje kompletny licznik wzoru na wariancję).
|
Numer klasy
|
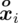 - środki przedziałów
- środki przedziałów
|
 - liczba klientów
- liczba klientów
|

|

|
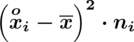
|
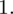
|

|

|
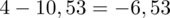
|
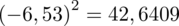
|
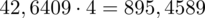
|

|

|

|
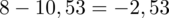
|
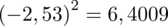
|

|

|

|

|
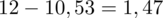
|
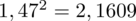
|
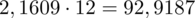
|

|

|

|
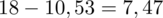
|
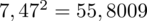
|
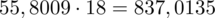
|
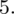
|

|
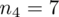
|
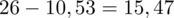
|
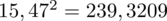
|
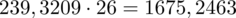
|

|
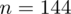
|
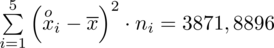
|
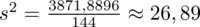
Skoro udało nam się obliczyć wartość
 , to możemy wreszcie wrócić do głównej istoty naszego zadania i uzupełniamy wzór
, to możemy wreszcie wrócić do głównej istoty naszego zadania i uzupełniamy wzór
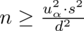 :
:
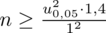
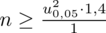
Teraz należy odczytać odpowiednią statystykę z tablic. W formule znajduje się literka
u
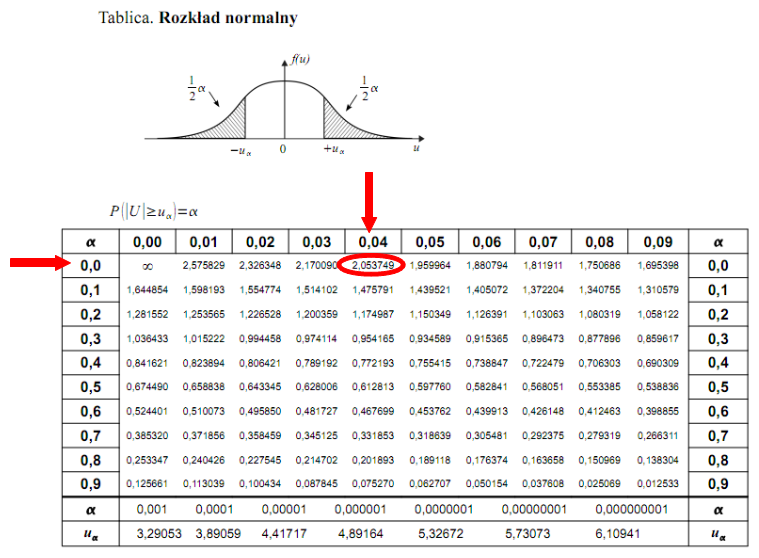
, zatem skorzystamy z tablic rozkładu normalnego:
http://matma-po-ludzku.pl/materialy/statystyka/wzory/rnormalny.pdf
. Zapis
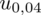 oznacza konieczność odnalezienia statystyki dla
oznacza konieczność odnalezienia statystyki dla
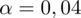 . Czytanie z tablic rozkładu normalnego nie jest trudne. Sumuje się wartości znajdujące się na obrzeżach tzn. z kolumny, która stanowi części dziesiętne i z wiersza, który traktujemy jako części setne. W przypadku
. Czytanie z tablic rozkładu normalnego nie jest trudne. Sumuje się wartości znajdujące się na obrzeżach tzn. z kolumny, która stanowi części dziesiętne i z wiersza, który traktujemy jako części setne. W przypadku
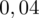 sumujemy
sumujemy
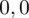 i
i
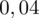 czyli
czyli
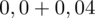 .
.
Wracamy do obliczeń i podstawiamy
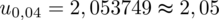 (zaokrąglanie to indywidualna sprawa wynikająca najczęściej z preferencji prowadzącego):
(zaokrąglanie to indywidualna sprawa wynikająca najczęściej z preferencji prowadzącego):
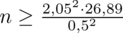
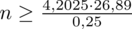
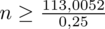
5. WYNIK I INTERPRETACJA.
Ostatecznie otrzymujemy:
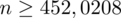 , czyli ZAWSZE zaokrąglając w górę otrzymujemy
, czyli ZAWSZE zaokrąglając w górę otrzymujemy
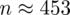 .
.
Interpretacja brzmi następująco: Aby oszacować średni czas w populacji generalnej klientów z ufnością 0,96 do próby należy wylosować 453 osób (należy dolosować
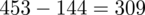 osób czyli próba nie jest wystarczająca).
osób czyli próba nie jest wystarczająca).