Spośród studentów Krakowa wylosowano 400 osób, które zapytano o palenie papierosów. 160 osób odpowiedziało twierdząco. Przyjmując współczynnik ufności
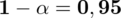 wskaż przedział ufności dla nieznanej częstości nałogu palenia w populacji studentów Krakowa.
wskaż przedział ufności dla nieznanej częstości nałogu palenia w populacji studentów Krakowa.
wskaż przedział ufności dla nieznanej częstości nałogu palenia w populacji studentów Krakowa.
a)
 b)
b)
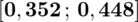 c)
c)
 d)
d)
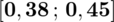
b)
c)
d)
1. JAK ROZPOZNAĆ ZADANIE DOTYCZĄCE ESTYMACJI PRZEDZIAŁOWEJ ?
Po przeczytaniu całego zadania zwracamy uwagę na zdanie:
Przyjmując współczynnik ufności
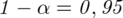 wskaż przedział ufności dla nieznanej częstości nałogu palenia w populacji studentów Krakowa.
wskaż przedział ufności dla nieznanej częstości nałogu palenia w populacji studentów Krakowa.
wskaż przedział ufności dla nieznanej częstości nałogu palenia w populacji studentów Krakowa.
Występują tu zwroty: wskaż przedział ufności oraz współczynnik ufności
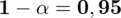 - w związku z tym na pewno jest to zadanie dotyczące estymacji przedziałowej.
- w związku z tym na pewno jest to zadanie dotyczące estymacji przedziałowej.
- w związku z tym na pewno jest to zadanie dotyczące estymacji przedziałowej.
2. ANALIZA I PRAWIDŁOWE WYPISANIE DANYCH.
Analizujemy zdanie po zdaniu.
Spośród studentów Krakowa wylosowano 400 osób, które zapytano o palenie papierosów.
Od razu zaczyna się opis próby, ponieważ pojawia się informacja na temat wylosowania konkretnej ilości studentów spośród całej populacji studentów Krakowa. Oznaczamy więc liczebność próby
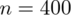 .
.
.
160 osób odpowiedziało twierdząco.
W tym momencie uzyskujemy informację, że 160 osób spośród 400 studentów pali papierosy - jest to ilość wyróżnionych obserwacji spośród próby. Opisujemy ją symbolem
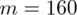 .
.
.
Przyjmując współczynnik ufności
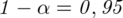 wskaż przedział ufności dla nieznanej częstości nałogu palenia w populacji studentów Krakowa.
wskaż przedział ufności dla nieznanej częstości nałogu palenia w populacji studentów Krakowa.
wskaż przedział ufności dla nieznanej częstości nałogu palenia w populacji studentów Krakowa.
Podano współczynnik ufności
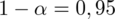 . Od razu wyznaczamy
. Od razu wyznaczamy
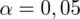 .
.
. Od razu wyznaczamy
.
Podsumowując tworzymy przejrzystą tabelę z danymi:
POPULACJA
studenci z Krakowa |
PRÓBA
400 wybranych studentów |
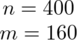
|
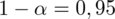 - współczynnik ufności,
- współczynnik ufności,
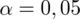
3. WYBÓR ODPOWIEDNIEGO WZORU.
Szukamy parametru, który należy oszacować przedziałem ufności i w ostatnim zdaniu wyłapujemy słowo:
Przyjmując współczynnik ufności
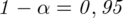 wskaż przedział ufności dla nieznanej częstości nałogu palenia w populacji studentów Krakowa.
wskaż przedział ufności dla nieznanej częstości nałogu palenia w populacji studentów Krakowa.
wskaż przedział ufności dla nieznanej częstości nałogu palenia w populacji studentów Krakowa.
Wyraz częstości oznacza, że będziemy budować przedział ufności dla wskaźnika struktury p z populacji. Na wskaźnik struktury wskazuje również wypisana w danych ilość wyróżnionych obserwacji spośród próby oznaczana jako m. Spójrzmy w kartę wzorów. Dla wskaźnika struktury mamy dwie formuły. W danych wypisano m w związku z tym wybieramy pierwszy wzór. Oczywiście można użyć drugiego wzoru, bo są one równoważne, ale na początku należy wyliczyć wskaźnik struktury z próby
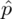 .
.
.
4. UZUPEŁNIANIE WYBRANEGO WZORU I OBLICZENIA.
Wracamy do danych z tabeli i uzupełniamy wzór
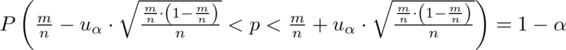 konkretnymi danymi.
konkretnymi danymi.
konkretnymi danymi.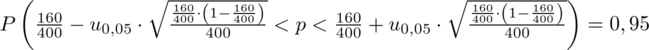
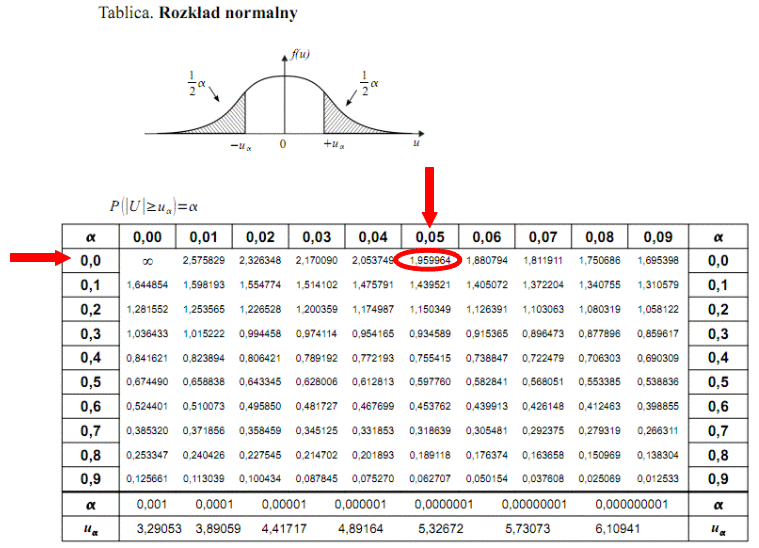
Teraz należy odczytać odpowiednią statystykę z tablic. W formule znajduje się literka u, zatem skorzystamy z tablic rozkładu normalnego (link). Zapis
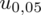 oznacza konieczność odnalezienia statystyki dla
oznacza konieczność odnalezienia statystyki dla
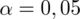 . Czytanie z tablic rozkładu normalnego nie jest trudne. Sumuje się wartości znajdujące się na obrzeżach tzn. z kolumny, która stanowi części dziesiętne i z wiersza, który traktujemy jako części setne. W przypadku
. Czytanie z tablic rozkładu normalnego nie jest trudne. Sumuje się wartości znajdujące się na obrzeżach tzn. z kolumny, która stanowi części dziesiętne i z wiersza, który traktujemy jako części setne. W przypadku
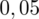 sumujemy
sumujemy
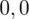 i
i
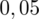 czyli
czyli
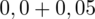 .
.
oznacza konieczność odnalezienia statystyki dla
. Czytanie z tablic rozkładu normalnego nie jest trudne. Sumuje się wartości znajdujące się na obrzeżach tzn. z kolumny, która stanowi części dziesiętne i z wiersza, który traktujemy jako części setne. W przypadku
sumujemy
i
czyli
.
Wracamy do obliczeń i podstawiamy
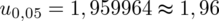 (zaokrąglanie to indywidualna sprawa wynikająca najczęściej z preferencji prowadzącego)
(zaokrąglanie to indywidualna sprawa wynikająca najczęściej z preferencji prowadzącego)
(zaokrąglanie to indywidualna sprawa wynikająca najczęściej z preferencji prowadzącego)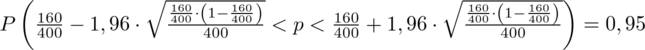
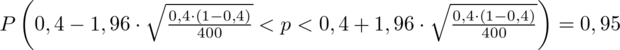
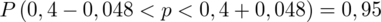
5. WYNIK I INTERPRETACJA.
Ostatecznie otrzymujemy:
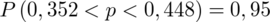
Interpretacja brzmi następująco: Z ufnością 0,95 nieznana częstość nałogu palenia w populacji studentów Krakowa mieści się w przedziale od 0,352 do 0,448. Prawidłowa jest zatem odpowiedź B.