ISBN 83-208-1107-4 str. 75
Audiometryczne badanie ubytku słuchu wybranych losowo pracowników dwóch wydziałów zakładu hutniczego (stalowni i walcowni) dostarczyło następujących informacji (dane w decybelach):
- dla 15-osobowej grupy pracowników walcowni otrzymano następujące wyniki: 53, 38, 47, 27, 34, 17, 69, 54, 35, 29, 62, 60, 30, 29, 59,
- w 10-osobowej grupie pracowników stalowni średni ubytek słuchu wynosi 38, a odchylenie standardowe 14,2.
Zakładając, że rozkłady ubytku słuchu w obu populacjach są zgodne z rozkładem normalnym, przy współczynniku ufności równym 0,90, zbudować przedział ufności dla wariancji ubytku słuchu wszystkich pracowników obu wydziałów.
1. JAK ROZPOZNAĆ ZADANIE DOTYCZĄCE ESTYMACJI PRZEDZIAŁOWEJ ?
Po przeczytaniu całego zadania zwracamy uwagę na zdanie:
Zakładając, że rozkłady ubytku słuchu w obu populacjach są zgodne z rozkładem normalnym, przy współczynniku ufności równym 0,90, zbudować przedział ufności dla wariancji ubytku słuchu wszystkich pracowników obu wydziałów.
Występują tu charakterystyczne dla tej grupy zadań zwroty: zbudować przedział ufności i współczynnik ufności - w związku z tym na pewno jest to zadanie dotyczące estymacji przedziałowej.
2. ANALIZA I PRAWIDŁOWE WYPISANIE DANYCH.
Analizujemy zdanie po zdaniu.
Audiometryczne badanie ubytku słuchu wybranych losowo pracowników dwóch wydziałów zakładu hutniczego (stalowni i walcowni) dostarczyło następujących informacji (dane w decybelach):
- dla 15-osobowej grupy pracowników walcowni otrzymano następujące wyniki: 53, 38, 47, 27, 34, 17, 69, 54, 35, 29, 62, 60, 30, 29, 59,
- w 10-osobowej grupie pracowników stalowni średni ubytek słuchu wynosi 38, a odchylenie standardowe 14,2.
Od razu zaczyna się opis próby, ponieważ pojawia się informacja na temat wylosowania konkretnej ilości pracowników zakładu hutniczego, ale uwaga - mamy do czynienia z dwiema oddzielnymi próbami. Jedną z nich stanowią pracownicy walcowni, a drugą - pracownicy stalowni. Pierwsza próba, czyli pracownicy walcowni liczy
 osób. Podano również informacje o konkretnych wynikach z próby. Jeżeli dysponujemy wartościami wypisanymi po przecinku tzw. danymi indywidualnymi, to zawsze możemy policzyć średnią
osób. Podano również informacje o konkretnych wynikach z próby. Jeżeli dysponujemy wartościami wypisanymi po przecinku tzw. danymi indywidualnymi, to zawsze możemy policzyć średnią
 , wariancję
, wariancję
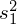 i odchylenie standardowe
i odchylenie standardowe
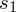 (lub
(lub
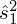 ,
,
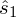 ). Nie liczmy jednak tych parametrów od razu, ponieważ dopiero etap wyboru formuły na estymację wskaże nam czego potrzebujemy. Po prostu chodzi o to, żeby nie liczyć na zapas np. odchylenia, bo może okazać się niepotrzebne w późniejszych obliczeniach. Druga próba, czyli gospodarstwa rolnicze liczy
). Nie liczmy jednak tych parametrów od razu, ponieważ dopiero etap wyboru formuły na estymację wskaże nam czego potrzebujemy. Po prostu chodzi o to, żeby nie liczyć na zapas np. odchylenia, bo może okazać się niepotrzebne w późniejszych obliczeniach. Druga próba, czyli gospodarstwa rolnicze liczy
 osób, a jej średnia wynosi
osób, a jej średnia wynosi
 oraz odchylenie standardowe
oraz odchylenie standardowe
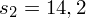 (oczywiście użyto oznaczeń parametrów dla próby).
(oczywiście użyto oznaczeń parametrów dla próby).
Zakładając, że rozkłady ubytku słuchu w obu populacjach są zgodne z rozkładem normalnym, przy współczynniku ufności równym 0,90, zbudować przedział ufności dla wariancji ubytku słuchu wszystkich pracowników obu wydziałów.
W tym zdaniu występuje założenie normalności rozkładów ubytku słuchu i to zawsze odnosi się do populacji (wcześniej wspominałam w części teoretycznej, że próba jest z reguły za mała aby stwierdzić rozkład normalny, poza tym pojawia wyraźnie się słowo populacja). Nie mamy informacji na temat tych rozkładów, zatem możemy tylko zapisać
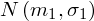 oraz
oraz
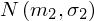 - rozkłady normalne o nieznanej średnich
- rozkłady normalne o nieznanej średnich
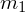 oraz
oraz
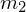 i nieznanych odchyleniach standardowych
i nieznanych odchyleniach standardowych
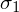 oraz
oraz
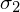 . Podano również współczynnik ufności, tak więc
. Podano również współczynnik ufności, tak więc
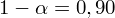 . Od razu wyznaczamy
. Od razu wyznaczamy
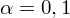 .
.
Podsumowując tworzymy przejrzystą tabelę z danymi:
|
POPULACJA
ogół pracowników dwóch wydziałów zakładu hutniczego
|
PRÓBA
wybrani pracownicy
|
||
|
pracownicy walcowni
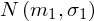 - rozkład normalny o nieznanej średniej
- rozkład normalny o nieznanej średniej
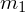 i nieznanym odchyleniu standardowym
i nieznanym odchyleniu standardowym
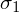
|
pracownicy stalowni
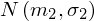 - rozkład normalny o nieznanej średniej
- rozkład normalny o nieznanej średniej
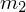 i nieznanym odchyleniu standardowym
i nieznanym odchyleniu standardowym
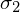
|
pracownicy walcowni
 ,
,
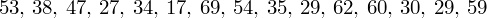 - dane indywidualne (można obliczyć średnią
- dane indywidualne (można obliczyć średnią
 , wariancję
, wariancję
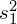 , odchylenie standardowe
, odchylenie standardowe
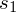 )
)
|
pracownicy stalowni


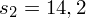
|
|
łączna liczebność próby:
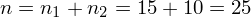
|
|||
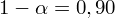 - współczynnik ufności,
- współczynnik ufności,
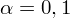
3. WYBÓR ODPOWIEDNIEGO WZORU.
Szukamy parametru, który należy oszacować przedziałem ufności i w ostatnim zdaniu wyłapujemy słowo:
Zakładając, że rozkłady ubytku słuchu w obu populacjach są zgodne z rozkładem normalnym, przy współczynniku ufności równym 0,90, zbudować przedział ufności dla wariancji ubytku słuchu wszystkich pracowników obu wydziałów.
Słowo
wariancja
oznacza, że będziemy budować przedział ufności oczywiście dla wariancji
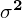 z populacji.
z populacji.
Spójrzmy w kartę wzorów. Dla wariancji mamy do wyboru dwa modele. Teraz wracamy do danych i sprawdzamy, czy jest
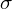 znana i jaka jest liczebność próby.
znana i jaka jest liczebność próby.
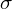 z żadnej populacji
nie jest znana
, a łączna liczebność próby
z żadnej populacji
nie jest znana
, a łączna liczebność próby
 jest mniejsza od 30
jest mniejsza od 30
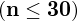 , zatem wybieramy
model I
. W danych z drugiej próby występuje
, zatem wybieramy
model I
. W danych z drugiej próby występuje
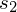 , a
, a
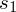 możemy obliczyć, ponieważ dysponujemy danymi indywidualnymi z drugiej próby, także interesuje nas pierwsza wersja wzoru z wybranego modelu.
możemy obliczyć, ponieważ dysponujemy danymi indywidualnymi z drugiej próby, także interesuje nas pierwsza wersja wzoru z wybranego modelu.

4. UZUPEŁNIANIE WYBRANEGO WZORU I OBLICZENIA.
Wracamy do danych z tabeli i uzupełniamy wzór
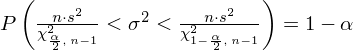 konkretnymi danymi.
konkretnymi danymi.
Niestety na tym etapie pojawia się problem, ponieważ w danych znajdują się dwa oddzielne odchylenia standardowe
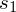 (które można obliczyć) i
(które można obliczyć) i
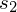 (lub wariancje
(lub wariancje
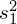 i
i
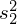 ), a do formuły należy wstawić
), a do formuły należy wstawić
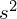 , czyli łączną wariancję dla obu prób (w końcu trzeba zbudować przedział ufności dla wariacji dla
całości
pracowników dwóch wydziałów zakładu hutniczego). Poszczególnych wariancji nie wolno po prostu zsumować, jak to zrobiono z próbami
, czyli łączną wariancję dla obu prób (w końcu trzeba zbudować przedział ufności dla wariacji dla
całości
pracowników dwóch wydziałów zakładu hutniczego). Poszczególnych wariancji nie wolno po prostu zsumować, jak to zrobiono z próbami
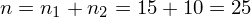 .
.
Aby obliczyć wariancję dla zbiorowości składającej się z kilku prób należy zastosować tzw. wariancję ogólną inaczej zwaną równością wariancyjną .
Wzór na równość wariancyjną wygląda następująco:
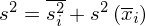 , gdzie:
, gdzie:
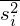 - wariacja wewnątrzgrupowa wyrażona wzorem
- wariacja wewnątrzgrupowa wyrażona wzorem
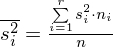 , rozumiana jako średnia arytmetyczna wariacji wewnątrzgrupowych
, rozumiana jako średnia arytmetyczna wariacji wewnątrzgrupowych
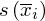 - wariancja zewnątrzgrupowa wyrażona wzorem
- wariancja zewnątrzgrupowa wyrażona wzorem
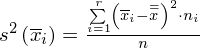 , rozumiana jako wariacja średnich z prób
, rozumiana jako wariacja średnich z prób
Na początek zajmiemy się wariancją wewnątrzgrupową
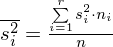 i wyjaśnimy symbole zawarte w tym wzorze.
i wyjaśnimy symbole zawarte w tym wzorze.
Znak
 oznacza sumę. Pod tym symbolem znajduje się zapis
oznacza sumę. Pod tym symbolem znajduje się zapis
 , a nad nim r ,
, a nad nim r ,
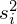 to wariancje kolejnych prób, a
to wariancje kolejnych prób, a
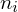 to liczebności tych prób. Wszytko razem oznacza, że będziemy sumować kolejne iloczyny
to liczebności tych prób. Wszytko razem oznacza, że będziemy sumować kolejne iloczyny
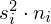 , gdzie
, gdzie
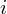 będzie rosło od
będzie rosło od
 aż do wartości
aż do wartości
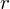 , czyli
, czyli
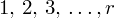 , a więc ogólnie:
, a więc ogólnie:
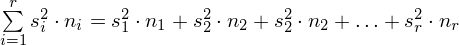
Wariacja wewnątrzgrupowa po rozpisaniu wygląda następująco:
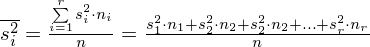
W naszym przypadku mamy dwie próby (pracownicy walcowni i stalowni), a więc
 , zatem wzór wygląda tak:
, zatem wzór wygląda tak:
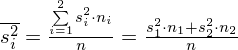
Jak widać brakuje tylko
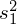 , więc dopóki nie znajdziemy wartości tego parametru nie możemy obliczyć wartości wariancji wewnątrzgrupowej. Wyliczanie wariacji z próby jest zagadnieniem ze statystki opisowej.
, więc dopóki nie znajdziemy wartości tego parametru nie możemy obliczyć wartości wariancji wewnątrzgrupowej. Wyliczanie wariacji z próby jest zagadnieniem ze statystki opisowej.
Dysponujemy danymi indywidualnymi (wynikami wypisanymi po przecinku), jest ich niewiele i praktycznie nie powtarzają się, zatem wariację liczymy ze wzoru związanego z danymi indywidualnymi:
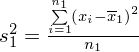 lub
lub
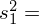
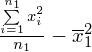 (obie wersje są równoważne, w praktyce pierwsza wersja jest częściej używana). Teraz okazuje się, że w formule pozwalającej wyznaczyć wariancję potrzebna jest wartość średnia
(obie wersje są równoważne, w praktyce pierwsza wersja jest częściej używana). Teraz okazuje się, że w formule pozwalającej wyznaczyć wariancję potrzebna jest wartość średnia
 , więc to od niej należy zacząć obliczenia.
, więc to od niej należy zacząć obliczenia.
Wzór na średnią z danych indywidualnych wygląda następująco:
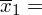
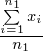 . Oczywiście na chłopski rozum średnią można policzyć sumując wszystkie dane, a potem dzieląc przez ilość – jest to jak najbardziej prawidłowe rozwiązanie, a podany wzór oznacza to samo. Jednak zdaję sobie sprawę, że widząc „hieroglify” tego typu wiele osób nie wie co robić, a tym bardziej jak je rozpisywać :). Mając to na uwadze postaram się przybliżyć kwestię podobnych oznaczeń rozpisując je na czynniki pierwsze.
. Oczywiście na chłopski rozum średnią można policzyć sumując wszystkie dane, a potem dzieląc przez ilość – jest to jak najbardziej prawidłowe rozwiązanie, a podany wzór oznacza to samo. Jednak zdaję sobie sprawę, że widząc „hieroglify” tego typu wiele osób nie wie co robić, a tym bardziej jak je rozpisywać :). Mając to na uwadze postaram się przybliżyć kwestię podobnych oznaczeń rozpisując je na czynniki pierwsze.
Znak
 to symbol sumy. Pod nim znajduje się zapis
to symbol sumy. Pod nim znajduje się zapis
 , a nad nim
, a nad nim
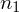 ,
,
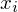 to wartości kolejnych obserwacji. Wszytko razem oznacza, że będziemy dodawać kolejne obserwacje oznaczone symbolem
to wartości kolejnych obserwacji. Wszytko razem oznacza, że będziemy dodawać kolejne obserwacje oznaczone symbolem
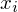 , gdzie
, gdzie
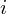 będzie rosło od
będzie rosło od
 aż do wartości
aż do wartości
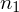 , a więc
, a więc
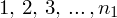 :
:
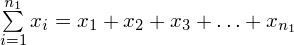
Tak więc średnia po rozpisaniu wygląda następująco:
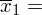
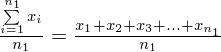
Teraz przełożymy wszystko na dane z zadania. Liczebność próby wynosi
 , a więc wzór na średnią możemy zapisać następująco:
, a więc wzór na średnią możemy zapisać następująco:
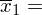
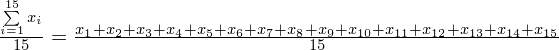
Czym jest
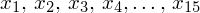 ? Są to konkretne wyniki z próby, a więc
? Są to konkretne wyniki z próby, a więc
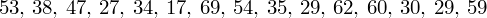 . Jeśli ktoś chciałby uporządkować dane indywidualne od najmniejszej do największej, może to spokojnie wykonać. Porządkowanie liczb nie wpływa na wartość średniej, także może zostać tak jak jest. A więc np.
. Jeśli ktoś chciałby uporządkować dane indywidualne od najmniejszej do największej, może to spokojnie wykonać. Porządkowanie liczb nie wpływa na wartość średniej, także może zostać tak jak jest. A więc np.
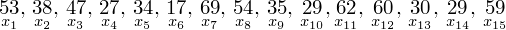 .
.
Obliczamy średnią:
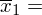
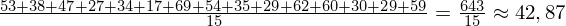
Dysponując wartością liczbową średniej możemy obliczyć wariancję
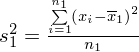 . Rozpisanie wzoru wykonujemy analogicznie jak w przypadku średniej. Na początek ogólnie:
. Rozpisanie wzoru wykonujemy analogicznie jak w przypadku średniej. Na początek ogólnie:
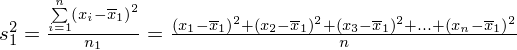
i dla
 :
:
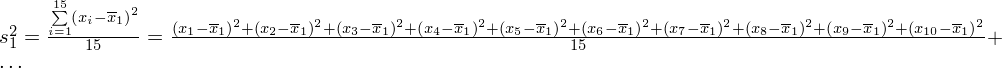
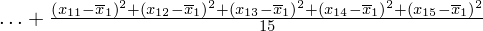
Możemy już podstawiać liczby za
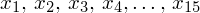 , ale proponuję utworzyć tabelkę i wykonywać w niej obliczenia. Po pierwsze jest bardziej klarowna, po drugie ułamek powstały po rozpisaniu wzoru jest tasiemcem i łatwo tu o pomyłkę. W tabelce powoli budujemy wzór na wariancję z danych indywidualnych, a jej nagłówki zawsze wyglądają tak samo. Na początku od każdej wartości
, ale proponuję utworzyć tabelkę i wykonywać w niej obliczenia. Po pierwsze jest bardziej klarowna, po drugie ułamek powstały po rozpisaniu wzoru jest tasiemcem i łatwo tu o pomyłkę. W tabelce powoli budujemy wzór na wariancję z danych indywidualnych, a jej nagłówki zawsze wyglądają tak samo. Na początku od każdej wartości
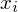 odejmujemy średnią, a następnie wynik podnosimy do kwadratu. Sumujemy ostatnią kolumnę (przecięcie wiersza z symbolem
odejmujemy średnią, a następnie wynik podnosimy do kwadratu. Sumujemy ostatnią kolumnę (przecięcie wiersza z symbolem
 i
i
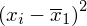 daje kompletny licznik wzoru na wariancję )
daje kompletny licznik wzoru na wariancję )
|

|
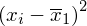
|
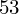
|
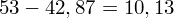
|
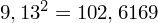
|
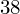
|
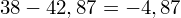
|
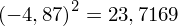
|
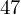
|
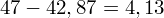
|
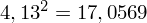
|
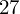
|
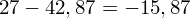
|
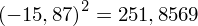
|

|
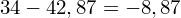
|
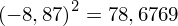
|
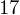
|
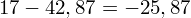
|
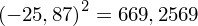
|
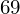
|
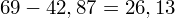
|
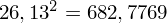
|
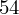
|
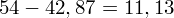
|
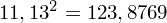
|
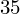
|
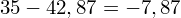
|
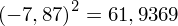
|

|
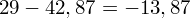
|
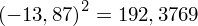
|
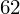
|
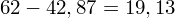
|
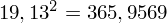
|
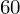
|
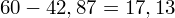
|
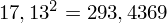
|
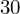
|
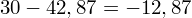
|
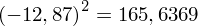
|

|
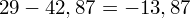
|
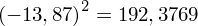
|
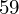
|
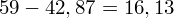
|
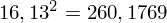
|
 (suma)
(suma)
|
|
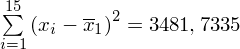
|
A więc
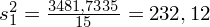
Wracamy do wzoru na wariancję wewnątrzgrupową
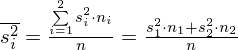 i podstawiamy dane:
i podstawiamy dane:
Oczywiście obliczenia można przeprowadzać w tabeli, ale stworzenie tabeli dla dwóch prób zajmie nam więcej czasu niż zwyczajne podstawienie do wzoru. Wracamy do danych i otrzymujemy:
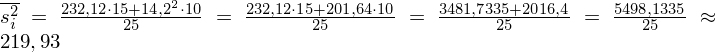
Teraz kolej na wariancję zewnątrzgrupową
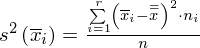 . Jak widać we wzorze znajduje się symbol
. Jak widać we wzorze znajduje się symbol
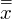 - jest to łączna średnia prób tzw. średnia średnich. W związku z tym musimy najpierw wyliczyć
- jest to łączna średnia prób tzw. średnia średnich. W związku z tym musimy najpierw wyliczyć
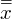 , a później zabierzemy się za wariancję zewnątrzgrupową. Wzór na średnią średnich wygląda następująco:
, a później zabierzemy się za wariancję zewnątrzgrupową. Wzór na średnią średnich wygląda następująco:
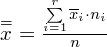 .
.
Rozpisanie analogiczne jak w przypadku poprzedniej formuły. Znak
 oznacza sumę. Pod tym symbolem znajduje się zapis
oznacza sumę. Pod tym symbolem znajduje się zapis
 , a nad nim
, a nad nim
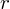 ,
,
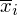 to średnie kolejnych próbek, a
to średnie kolejnych próbek, a
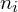 to liczebności poszczególnych prób. Wszytko razem oznacza, że będziemy sumować kolejne iloczyny
to liczebności poszczególnych prób. Wszytko razem oznacza, że będziemy sumować kolejne iloczyny
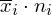 , gdzie
, gdzie
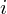 będzie rosło od
będzie rosło od
 aż do wartości
aż do wartości
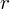 , czyli
, czyli
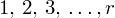 , a więc ogólnie:
, a więc ogólnie:
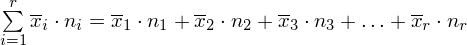
Średnia średnich prezentuje się zatem następująco:
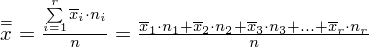
W naszym przypadku mamy dwie próby (pracownicy walcowni i stalowni), a więc
 , zatem wzór wygląda tak:
, zatem wzór wygląda tak:
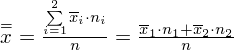
Podstawiając dane z tabeli i wyliczoną po drodze
 otrzymujemy:
otrzymujemy:
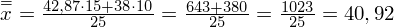
Uprzedzam, że liczenie średniej średnich poprzez dodanie obu średnich i podzielenie na dwa jest NIEPRAWIDŁOWE! Jest to możliwe wyłącznie w przypadku, gdzie liczebności poszczególnych grup są jednakowe. Dla różnych liczebności próbek stosuje się powyższy wzór. To zasada dotyczy również wariacji wewnątrzgrupowej.
Wracamy do wariancji zewnątrzgrupowej
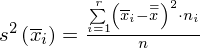 . I znów rozpisanie wzoru jak wcześniej. Znak
. I znów rozpisanie wzoru jak wcześniej. Znak
 oznacza sumę. Pod tym symbolem znajduje się zapis
oznacza sumę. Pod tym symbolem znajduje się zapis
 , a nad nim
, a nad nim
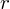 ,
,
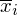 to średnie kolejnych próbek, a
to średnie kolejnych próbek, a
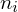 to liczebności poszczególnych prób. Wszytko razem oznacza, że będziemy od każdej średniej z próby odejmować średnią średnich, otrzymaną różnicę podnosimy następnie do kwadratu i wymnażamy przez liczebność danej próby. Na koniec sumujemy powstałe wyniki
to liczebności poszczególnych prób. Wszytko razem oznacza, że będziemy od każdej średniej z próby odejmować średnią średnich, otrzymaną różnicę podnosimy następnie do kwadratu i wymnażamy przez liczebność danej próby. Na koniec sumujemy powstałe wyniki
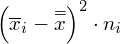 , gdzie
, gdzie
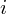 będzie rosło od
będzie rosło od
 aż do wartości
aż do wartości
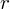 , czyli
, czyli
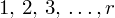 , a więc ogólnie:
, a więc ogólnie:
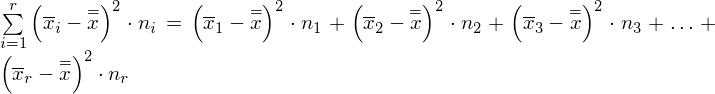
Wariancja zewnątrzgrupowa:
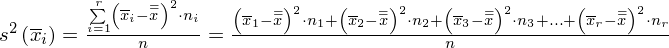
W naszym przypadku mamy dwie próby (pracownicy walcowni i stalowni), a więc
 , zatem wzór wygląda tak:
, zatem wzór wygląda tak:
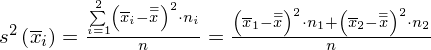
Podstawiając dane z tabeli otrzymujemy:
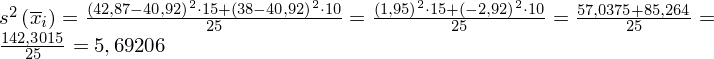
Możemy wreszcie wyliczyć wariację ogólną
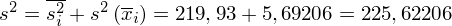 .
.
Wracamy do istoty zadania i uzupełniamy wzór
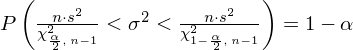 :
:
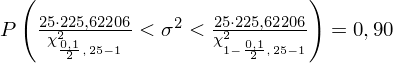
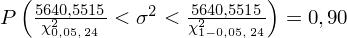
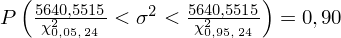
Teraz należy odczytać odpowiednią statystykę z tablic. W formule znajduje się literka
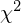 (grecka litera czyt.
chi
), zatem skorzystamy z tablic rozkładu chi-kwadrat (link). W tym przypadku będziemy odczytywać statystykę dwukrotnie, ponieważ w uzupełnionym wzorze występują dwa nieco różniące się symbole:
(grecka litera czyt.
chi
), zatem skorzystamy z tablic rozkładu chi-kwadrat (link). W tym przypadku będziemy odczytywać statystykę dwukrotnie, ponieważ w uzupełnionym wzorze występują dwa nieco różniące się symbole:
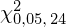 oraz
oraz
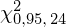 . Zapis
. Zapis
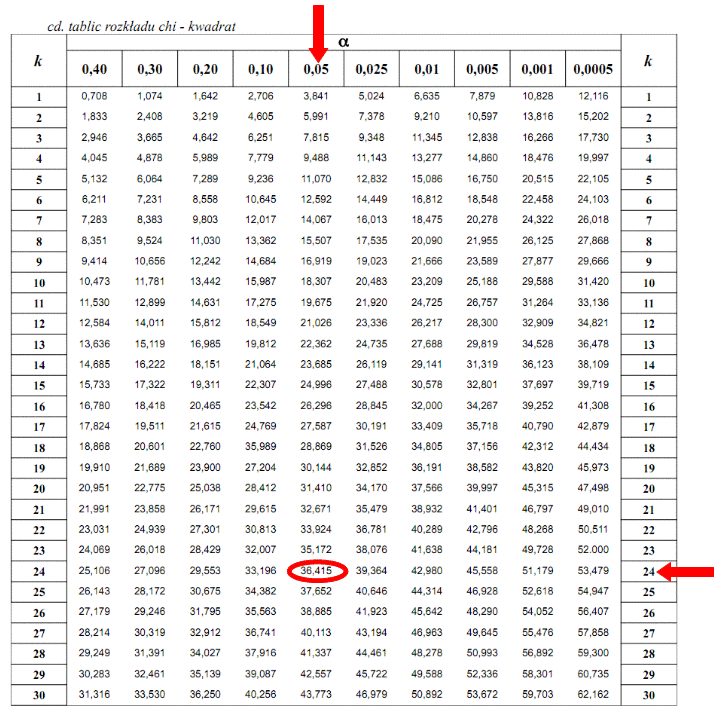
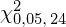 oznacza konieczność odnalezienia w tablicach statystyki dla
oznacza konieczność odnalezienia w tablicach statystyki dla
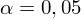 i 24 stopni swobody:
i 24 stopni swobody:
Z kolei zapis
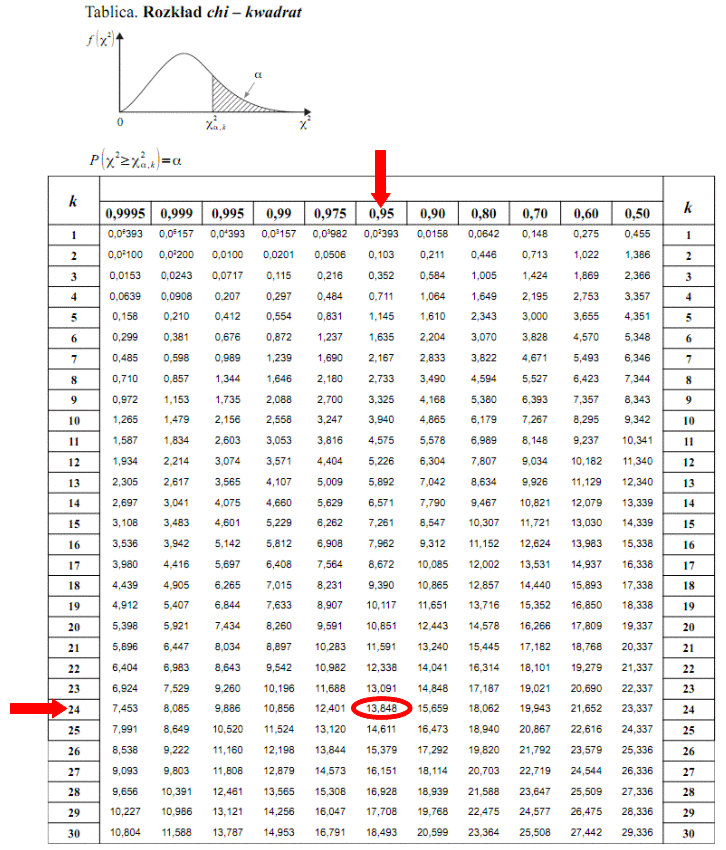
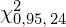 oznacza konieczność odnalezienia w tablicach statystyki dla
oznacza konieczność odnalezienia w tablicach statystyki dla
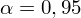 i 24 stopni swobody:
i 24 stopni swobody:
Wracamy do obliczeń i podstawiamy
 oraz
oraz
 :
:
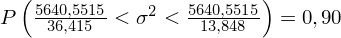
5. WYNIK I INTERPRETACJA.
Ostatecznie otrzymujemy:
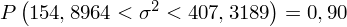
Interpretacja brzmi następująco: Z ufnością 0,90 nieznana wariancja ubytku słuchu wszystkich pracowników obu wydziałów mieści się w przedziale od 154,8964 do 407,3189 (decybeli) 2 .
Powstała dziwna jednostka - (decybele) 2 , ale w przypadku wariancji (jednostka podniesiona do kwadratu) nie jest to nic nadzwyczajnego i nie należy na to zwracać większej uwagi. Przyjęło się zresztą, że samej wariancji się nie interpretuje, ale już odchylenie standardowe, które jest pierwiastkiem z wariancji - jak najbardziej.