Zadanie 39
W ciągu wybranych w sposób losowy 100 dni, liczba wypadków przy pracy w kopalniach kształtowała się następująco:
|
Liczba wypadków |
0 |
1 |
2 |
3 |
4 |
5 |
|
Liczba dni |
35 |
44 |
9 |
6 |
4 |
2 |
Przyjmując współczynnik ufności 0,95, oszacować średnią dzienną liczbę wypadków przy pracy w kopalniach.
1. JAK ROZPOZNAĆ ZADANIE DOTYCZĄCE ESTYMACJI PRZEDZIAŁOWEJ ?
Po przeczytaniu całego zadania zwracamy uwagę na ostatnie zdanie:
„Przyjmując współczynnik ufności 0,95, oszacować średnią dzienną liczbę wypadków przy pracy w kopalniach.”
Co prawda nie użyto bezpośrednio zwrotu przedział ufności, ale musimy oszacować liczbę wypadków, więc wypadałoby podać przedział ufności, bo tzw. estymacja punktowa (tzn. konkretna liczba, a nie przedział) daje wynik o prawdopodobieństwie praktycznie równym zero. Dodatkowo występuje tu wyrażenie: współczynnik ufności i w związku z tym na pewno jest to zadanie dotyczące estymacji przedziałowej.
2. ANALIZA I PRAWIDŁOWE WYPISANIE DANYCH.
Analizujemy zdanie po zdaniu.
„W ciągu wybranych w sposób losowy 100 dni, liczba wypadków przy pracy w kopalniach kształtowała się następująco:”
|
Liczba wypadków |
0 |
1 |
2 |
3 |
4 |
5 |
|
Liczba dni |
35 |
44 |
9 |
6 |
4 |
2 |
Od razu zaczyna się opis próby, ponieważ pojawia się informacja o wybraniu konkretnej ilości dni, tak więc liczebność próby to 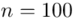 . Podano również wyniki z próby w tabeli. Jeżeli dysponujemy danymi dotyczącymi próby ujętymi w tabeli zawsze możemy policzyć średnią
. Podano również wyniki z próby w tabeli. Jeżeli dysponujemy danymi dotyczącymi próby ujętymi w tabeli zawsze możemy policzyć średnią 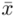 , wariancję
, wariancję 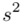 i odchylenie standardowe
i odchylenie standardowe 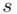 (lub
(lub 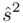 ,
, 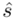 ). Nie liczmy jednak tych parametrów od razu, ponieważ dopiero etap wyboru formuły na estymację wskaże nam czego potrzebujemy. Po prostu chodzi o to, żeby nie liczyć na zapas np. odchylenia, bo może okazać się niepotrzebne w późniejszych obliczeniach.
). Nie liczmy jednak tych parametrów od razu, ponieważ dopiero etap wyboru formuły na estymację wskaże nam czego potrzebujemy. Po prostu chodzi o to, żeby nie liczyć na zapas np. odchylenia, bo może okazać się niepotrzebne w późniejszych obliczeniach.
„Przyjmując współczynnik ufności 0,95, oszacować średnią dzienną liczbę wypadków przy pracy w kopalniach.”
Podano współczynnik ufności 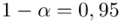 . Od razu wyznaczamy
. Od razu wyznaczamy 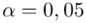 .
.
Podsumowując tworzymy przejrzystą tabelę z danymi:
|
POPULACJA dni pracy w kopalni |
PRÓBA 100 wybranych dni |
|
|
dane tabelaryczne (można obliczyć średnią |
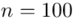
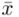 , wariancję
, wariancję 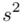 , odchylenie standardowe
, odchylenie standardowe 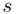 )
) 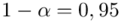 - współczynnik ufności,
- współczynnik ufności, 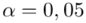
3. WYBÓR ODPOWIEDNIEGO WZORU.
Szukamy parametru, który należy oszacować przedziałem ufności i w ostatnim zdaniu wyłapujemy słowo:
„Przyjmując współczynnik ufności 0,95, oszacować średnią dzienną liczbę wypadków przy pracy w kopalniach.”
Wyraz średnią oznacza, że będziemy budować przedział ufności dla wartości średniej 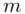 z populacji.
z populacji.
Spójrzmy w kartę wzorów. Dla średniej mamy do wyboru trzy modele wzorów. Teraz wracamy do danych i sprawdzamy, czy 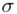 jest znana i jaka jest liczebność próby.
jest znana i jaka jest liczebność próby. 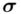 nie jest znana, a liczebność próby
nie jest znana, a liczebność próby 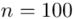 jest większa od 30 (
jest większa od 30 ( 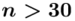 ), zatem wybieramy model III.
), zatem wybieramy model III.

4. UZUPEŁNIANIE WYBRANEGO WZORU I OBLICZENIA.
Wracamy do danych w tabeli i uzupełniamy wzór 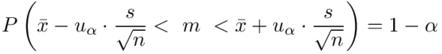 konkretnymi liczbami. Jak widać potrzebujemy średniej z próby
konkretnymi liczbami. Jak widać potrzebujemy średniej z próby 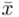 i odchylenia standardowego
i odchylenia standardowego 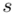 . W związku z tym zanim zajmiemy się uzupełnianiem właściwego wzoru należy obliczyć dwa (na razie) nieznane parametry.
. W związku z tym zanim zajmiemy się uzupełnianiem właściwego wzoru należy obliczyć dwa (na razie) nieznane parametry.
Liczenie średniej, wariacji i odchylenia standardowego jest zagadnieniem ze statystyki opisowej. Dysponujemy danymi tabelarycznymi, gdzie warianty cechy nie są w formie przedziałów tzn. od … do... , tylko konkretnymi liczbami tzw. danymi punktowymi. Tak więc mamy do czynienia z szeregiem punktowym. Przeredagujmy zatem tabelę z zadania właśnie na ten szereg.
|
(liczba wypadków) |
(liczba dni) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
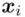 - warianty obserwacji
- warianty obserwacji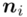 - liczebności poszczególnych obserwacji
- liczebności poszczególnych obserwacji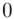
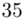
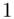
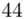
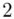
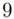
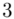
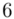
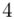
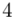
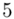
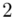
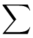 (suma)
(suma)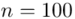
Częstym problemem jest określenie, które dane należy określić oznaczeniem 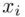 , a które
, a które 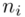 . Najłatwiej rozpoznać
. Najłatwiej rozpoznać 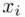 po tym, że liczby są w kolejności albo są uporządkowane. Wartości
po tym, że liczby są w kolejności albo są uporządkowane. Wartości 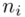 praktycznie nigdy nie są ustawione kolejno. Podobną sytuację mamy w powyższej tabeli.
praktycznie nigdy nie są ustawione kolejno. Podobną sytuację mamy w powyższej tabeli.
W szeregu punktowym średnią liczymy ze wzoru 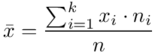 . Objaśnijmy go. Znak
. Objaśnijmy go. Znak 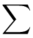 oznacza sumę. Pod tym symbolem znajduje się zapis
oznacza sumę. Pod tym symbolem znajduje się zapis 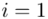 , a nad nim
, a nad nim 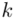 ,
, 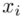 to wartości kolejnych obserwacji, a
to wartości kolejnych obserwacji, a 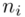 liczebności dla tych obserwacji. Wszytko razem oznacza, że będziemy sumować kolejne iloczyny
liczebności dla tych obserwacji. Wszytko razem oznacza, że będziemy sumować kolejne iloczyny 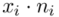 , gdzie
, gdzie 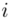 będzie rosło od
będzie rosło od 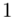 aż do wartości
aż do wartości 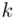 , a więc
, a więc 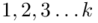 , a więc ogólnie:
, a więc ogólnie:
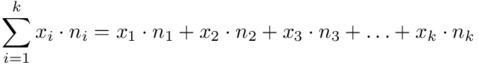
W naszym przypadku 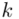 znad znaku sumy oznacza liczbę klas (ilość wierszy w tabeli z danymi, ilość wariantów obserwacji). Tak więc średnia będzie miała uproszczony wzór:
znad znaku sumy oznacza liczbę klas (ilość wierszy w tabeli z danymi, ilość wariantów obserwacji). Tak więc średnia będzie miała uproszczony wzór:
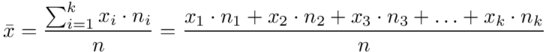
Czym jest 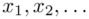 ,
, 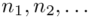 oraz
oraz 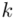 ? Wszystko to pokażmy dokładnie w tabeli:
? Wszystko to pokażmy dokładnie w tabeli:
|
Numer klasy |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
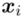 - warianty obserwacji
- warianty obserwacji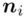 - liczebności poszczególnych obserwacji
- liczebności poszczególnych obserwacji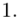
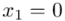
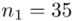
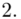
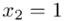
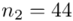
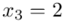
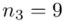
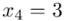
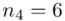
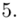
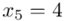
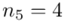
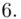
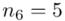
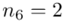
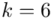
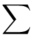 (suma)
(suma)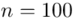
Uzupełniając 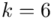 otrzymujemy wzór:
otrzymujemy wzór:
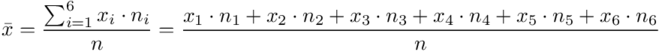 i oczywiście możemy uzupełnić go danymi z tabeli, ale proponuję nadal korzystać z tabeli i wykonywać w niej obliczenia. Po pierwsze jest bardziej klarowna, po drugie ułamek powstały po rozpisaniu wzoru może okazać się dłuższym tasiemcem niż w tym konkretnym zadaniu i łatwo tu o pomyłkę. W tabelce powoli budujemy wzór na średnią z szeregu punktowego, a jej nagłówki zawsze wyglądają tak samo. Każdą wartość
i oczywiście możemy uzupełnić go danymi z tabeli, ale proponuję nadal korzystać z tabeli i wykonywać w niej obliczenia. Po pierwsze jest bardziej klarowna, po drugie ułamek powstały po rozpisaniu wzoru może okazać się dłuższym tasiemcem niż w tym konkretnym zadaniu i łatwo tu o pomyłkę. W tabelce powoli budujemy wzór na średnią z szeregu punktowego, a jej nagłówki zawsze wyglądają tak samo. Każdą wartość 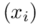 mnożymy przez odpowiadającą mu wartość
mnożymy przez odpowiadającą mu wartość 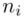 , a następnie sumujemy powstałe iloczyny. Przecięcie wiersza z symbolem
, a następnie sumujemy powstałe iloczyny. Przecięcie wiersza z symbolem 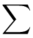 i kolumny
i kolumny 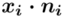 daje kompletny licznik wzoru na średnią.
daje kompletny licznik wzoru na średnią.
|
Numer klasy |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
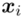 - warianty obserwacji
- warianty obserwacji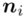 - liczebności poszczególnych obserwacji
- liczebności poszczególnych obserwacji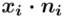
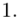
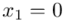
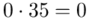
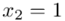
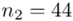
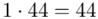
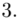
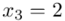
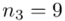
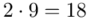
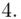
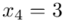
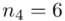
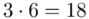
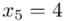
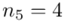
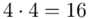
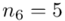
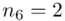
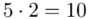
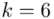
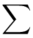 (suma)
(suma)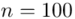
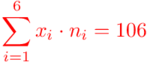
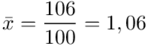
Zostało nam jeszcze odchylenie standardowe 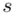 . Na początek i tak musimy obliczyć wariancję
. Na początek i tak musimy obliczyć wariancję 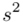 , bo
, bo 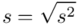 . Wzór na wariancję z danych szeregu punktowego wygląda następująco:
. Wzór na wariancję z danych szeregu punktowego wygląda następująco: 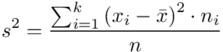 . Jest też alternatywa
. Jest też alternatywa 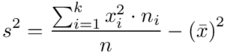 , ale będziemy używać pierwszej wersji. Rozpisanie wzoru analogiczne jak w przypadku średniej. Jak widać do policzenia wariancji i tak niezbędna jest średnia. Na początek ogólnie:
, ale będziemy używać pierwszej wersji. Rozpisanie wzoru analogiczne jak w przypadku średniej. Jak widać do policzenia wariancji i tak niezbędna jest średnia. Na początek ogólnie:
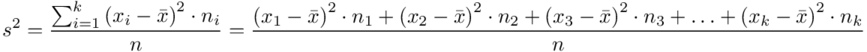
i dla ilości klas z zadania 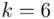 :
:
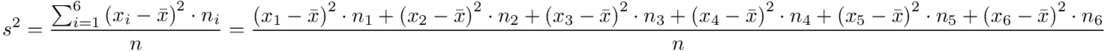
Tu też można podstawiać dane z tabeli, ale ponownie proponuję trzymać się obliczeń tabelarycznych. Można kontynuować poprzednią tabelę dopisując kolejne kolumny. Znowu krok po kroku będziemy tworzyć licznik ze wzoru. Dopisana pierwsza kolumna - od każdej wariantu cechy 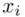 odejmujemy wcześniej wyliczoną średnią
odejmujemy wcześniej wyliczoną średnią 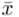 , druga kolumna to podniesienie wyników z poprzedniej do kwadratu. Ostatnia to wymnożenie wyników z drugiej przez odpowiadające im wartości
, druga kolumna to podniesienie wyników z poprzedniej do kwadratu. Ostatnia to wymnożenie wyników z drugiej przez odpowiadające im wartości 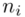 i dopiero ona jest sumowana (przecięcie wiersza z symbolem
i dopiero ona jest sumowana (przecięcie wiersza z symbolem 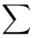 i
i 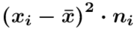 daje kompletny licznik wzoru na wariancję ).
daje kompletny licznik wzoru na wariancję ).
|
Numer klasy |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
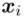 - warianty obserwacji
- warianty obserwacji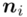 - liczebności poszczególnych obserwacji
- liczebności poszczególnych obserwacji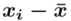
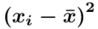
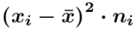
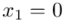
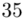
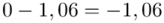
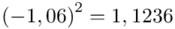
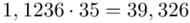
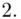
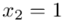
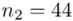
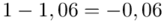
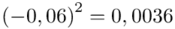
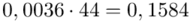
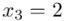
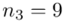
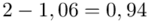
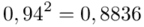
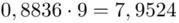
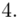
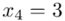
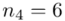
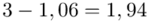
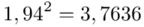
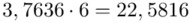
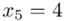
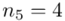
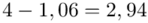
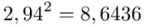
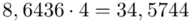
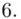
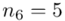
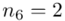
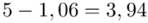
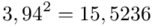
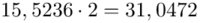
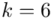
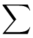 (suma)
(suma)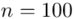
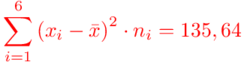
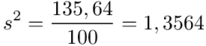
Odchylenie standardowe 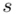 to pierwiastek z wariancji
to pierwiastek z wariancji 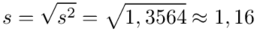 .
.
Wracamy do istoty zadania i wreszcie uzupełniamy wzór 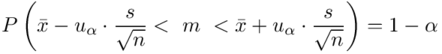 :
:
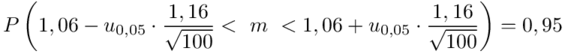
Teraz należy odczytać odpowiednią statystykę z tablic. W formule znajduje się literka u, zatem skorzystamy z tablic rozkładu normalnego. Zapis 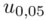 oznacza konieczność odnalezienia statystyki dla
oznacza konieczność odnalezienia statystyki dla 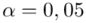 .
.
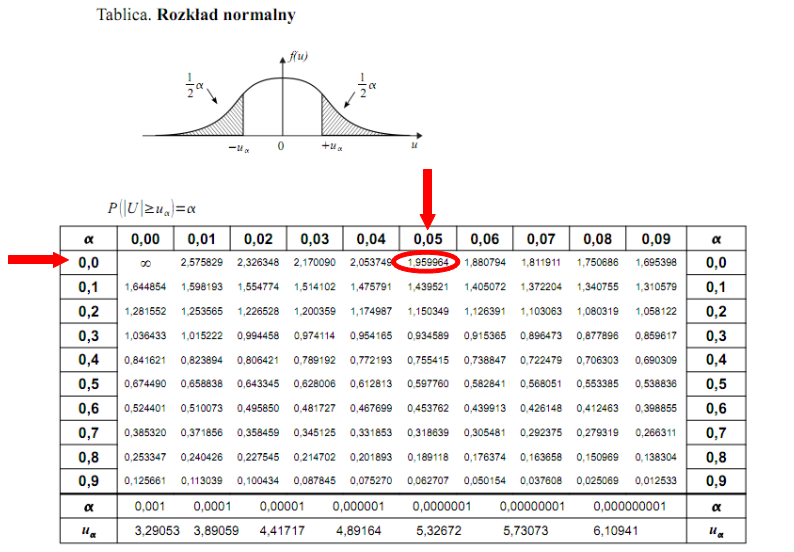
Czytanie z tablic rozkładu normalnego nie jest trudne. Sumuje się wartości znajdujące się na obrzeżach tzn. z kolumny, która stanowi części dziesiętne i z wiersza, który traktujemy jako części setne. W przypadku 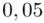 sumujemy
sumujemy 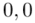 i
i 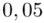 czyli
czyli 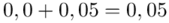 .
.
Wracamy do obliczeń i podstawiamy 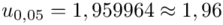 (zaokrąglanie to indywidualna sprawa wynikająca najczęściej z preferencji prowadzącego)
(zaokrąglanie to indywidualna sprawa wynikająca najczęściej z preferencji prowadzącego)
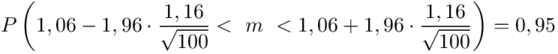
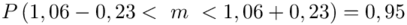
5. WYNIK I INTERPRETACJA.
Ostatecznie otrzymujemy: 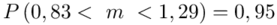
Interpretacja brzmi następująco:
Z ufnością 0,95 średnia liczba wypadków pracowniczych mieści się w przedziale od 0,83 do 1,29.
Statystyka: podstawy teoretyczne, przykłady, zadania / Mieczysław Sobczyk. - Wyd.1 - Lublin : Wydaw.Uniw.M.Curie-Skłodowskiej, 2000 - 425 s. ; 25 cm. - ISBN 83-227-1608-7