Zadanie 15
Na podstawie informacji o czasie przepisywania na komputerze jednej strony tekstu przez 100 losowo wybranych maszynistek oszacowano przedział dla średniego czasu pisania jednej strony tekstu przez ogół maszynistek: 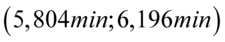 . Wiedząc dodatkowo, że rozkład czasu pisania jednej strony tekstu jest zbliżony do normalnego i że odchylenie standardowe w wylosowanej próbie wynosiło 1 min. ustalić, jaki współczynnik ufności przyjęto przy szacowaniu powyższego przedziału.
. Wiedząc dodatkowo, że rozkład czasu pisania jednej strony tekstu jest zbliżony do normalnego i że odchylenie standardowe w wylosowanej próbie wynosiło 1 min. ustalić, jaki współczynnik ufności przyjęto przy szacowaniu powyższego przedziału.
1. JAK ROZPOZNAĆ ZADANIE DOTYCZĄCE ESTYMACJI PRZEDZIAŁOWEJ ?
Zwracamy uwagę na zdanie:
„Na podstawie informacji o czasie przepisywania na komputerze jednej strony tekstu przez 100 losowo wybranych maszynistek oszacowano przedział dla średniego czasu pisania jednej strony tekstu przez ogół maszynistek: 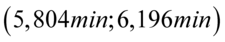 .”
.”
Odnajdujemy w nim słowo: przedział.
„Wiedząc dodatkowo, że rozkład czasu pisania jednej strony tekstu jest zbliżony do normalnego i że odchylenie standardowe w wylosowanej próbie wynosiło 1 min. ustalić, jaki współczynnik ufności przyjęto przy szacowaniu powyższego przedziału.”
W ostatnim zdaniu również występuje słowo przedział. Dodatkowym potwierdzeniem, że zadanie dotyczy estymacji przedziałowej jest wyrażenie: współczynnik ufności.
W związku z tym, że podane są końcówki przedziału ufności ( 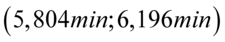 ), a szukany jest współczynnik ufności
), a szukany jest współczynnik ufności 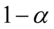 z reguły występujący w danych, określimy to zadanie nieco kolokwialnie - „od tyłu”. Mimo to, będziemy postępować zgodnie z przyjętym schematem do zadań z estymacji i tylko na pewnym etapie obliczeń wprowadzimy modyfikacje.
z reguły występujący w danych, określimy to zadanie nieco kolokwialnie - „od tyłu”. Mimo to, będziemy postępować zgodnie z przyjętym schematem do zadań z estymacji i tylko na pewnym etapie obliczeń wprowadzimy modyfikacje.
2. ANALIZA I PRAWIDŁOWE WYPISANIE DANYCH.
Analizujemy zdanie po zdaniu.
„Na podstawie informacji o czasie przepisywania na komputerze jednej strony tekstu przez 100 losowo wybranych maszynistek oszacowano przedział dla średniego czasu pisania jednej strony tekstu przez ogół maszynistek: 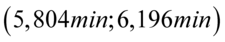 .”
.”
W tym momencie dowiadujemy się, że wybrano 100 maszynistek, a więc podano liczebność próby: 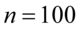 . Podano również końcówki przedziału ufności. Wiemy, że średni czas pisania dla populacji (ogółu) maszynistek zawarta jest w przedziale od 5,804 min. do 6,196 min.
. Podano również końcówki przedziału ufności. Wiemy, że średni czas pisania dla populacji (ogółu) maszynistek zawarta jest w przedziale od 5,804 min. do 6,196 min.
„Wiedząc dodatkowo, że rozkład czasu pisania jednej strony tekstu jest zbliżony do normalnego i że odchylenie standardowe w wylosowanej próbie wynosiło 1 min. ustalić, jaki współczynnik ufności przyjęto przy szacowaniu powyższego przedziału.”
W zadaniu występuje założenie normalności rozkładu i to już odnosi się do populacji (wcześniej wspominałam w części teoretycznej, że próba jest z reguły za mała aby stwierdzić rozkład normalny). Nie mamy informacji na temat tego rozkładu, zatem możemy tylko zapisać 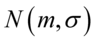 - rozkład normalny o nieznanej średniej
- rozkład normalny o nieznanej średniej 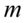 i nieznanym odchyleniu standardowym
i nieznanym odchyleniu standardowym 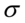 . Podano również odchylenie standardowe dla próby, a więc
. Podano również odchylenie standardowe dla próby, a więc  . Oczywiście użyliśmy oznaczenia dla próby. Naszą niewiadomą jest współczynnik ufności
. Oczywiście użyliśmy oznaczenia dla próby. Naszą niewiadomą jest współczynnik ufności 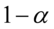 .
.
Podsumowując tworzymy przejrzystą tabelę z danymi:
|
POPULACJA ogół maszynistek |
PRÓBA 100 wybranych maszynistek |
|
|
|
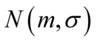 - rozkład normalny o nieznanej średniej
- rozkład normalny o nieznanej średniej 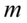 i nieznanym odchyleniu standardowym
i nieznanym odchyleniu standardowym 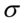
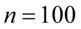
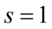
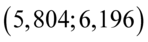 - końcówki przedziału ufności dla średniej z populacji
- końcówki przedziału ufności dla średniej z populacji
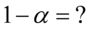 - współczynnik ufności,
- współczynnik ufności, 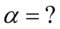
3. WYBÓR ODPOWIEDNIEGO WZORU.
Szukamy parametru, który został oszacowany przedziałem ufności. Przyjrzyjmy się zdaniu:
„...oszacowano przedział dla średniego czasu pisania jednej strony tekstu przez ogół maszynistek: 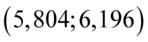 ”
”
Podano tu końcówki przedziału ufności dla średniej z populacji 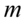 - przypominam, że przedział ufności jest budowany dla parametrów z populacji i dlatego nie
- przypominam, że przedział ufności jest budowany dla parametrów z populacji i dlatego nie 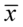 tylko
tylko 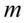 .
.
Spójrzmy w kartę wzorów. Dla średniej mamy do wyboru trzy modele wzorów. Teraz wracamy do danych i sprawdzamy, czy 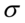 jest znana i jaka jest liczebność próby.
jest znana i jaka jest liczebność próby. 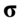 nie jest znana, a liczebność próby
nie jest znana, a liczebność próby 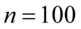 jest większa od 30 (
jest większa od 30 ( 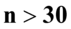 ), zatem wybieramy model III.
), zatem wybieramy model III.

4. UZUPEŁNIANIE WYBRANEGO WZORU I OBLICZENIA.
Wracamy do danych w tabeli i uzupełniamy wzór 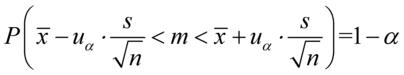 konkretnymi liczbami.
konkretnymi liczbami.
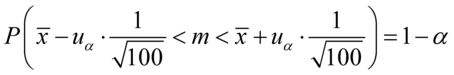
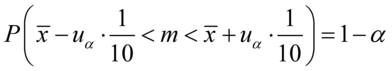
Jak widać, nie możemy uzupełnić współczynnika ufności  , a tym samym nieznana jest
, a tym samym nieznana jest 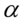 , więc na tym etapie nie mamy możliwości odczytania odpowiedniej statystyki z tablic rozkładu normalnego (bo w formule znajduje się literka u). Znamy jednak końcówki przedziału ufności i w związku z tym możemy je pomocniczo nanieść do wzoru.
, więc na tym etapie nie mamy możliwości odczytania odpowiedniej statystyki z tablic rozkładu normalnego (bo w formule znajduje się literka u). Znamy jednak końcówki przedziału ufności i w związku z tym możemy je pomocniczo nanieść do wzoru.
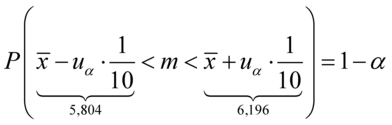
Nie znamy wartości 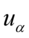 oraz
oraz 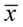 , więc potraktujmy je jako niewiadome i rozwiążmy układ równań aby je wyznaczyć. Zwykła matematyczna zasada – mając dwie niewiadome potrzebujemy z reguły dwóch równań. Pierwsze równanie dotyczy 5,804, a drugie 6,196. Zapisujemy zatem:
, więc potraktujmy je jako niewiadome i rozwiążmy układ równań aby je wyznaczyć. Zwykła matematyczna zasada – mając dwie niewiadome potrzebujemy z reguły dwóch równań. Pierwsze równanie dotyczy 5,804, a drugie 6,196. Zapisujemy zatem:
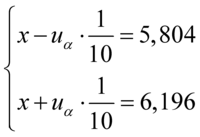

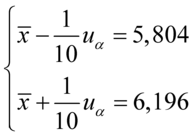
Sposób rozwiązania układu jest dowolny, chociaż tu najwygodniej zastosować metodę przeciwnych współczynników. Dodajemy stronami obydwa równania:
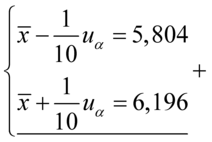
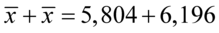
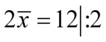
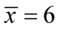
Wracamy do układu i wybierając dowolne równanie wyliczamy 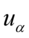 , sama średnia
, sama średnia 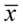 chociaż już wyliczona nie jest przez nas poszukiwana:
chociaż już wyliczona nie jest przez nas poszukiwana:
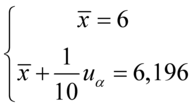

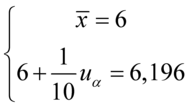

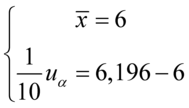

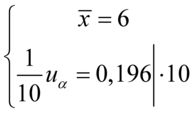

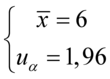
Jeśli komuś z Was jest wygodniej rozwiązywać układy równań z literką 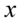 i
i 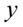 , to możecie spokojnie na początku zastąpić symbole np.
, to możecie spokojnie na początku zastąpić symbole np. 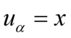 i
i 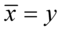 lub odwrotnie.
lub odwrotnie.
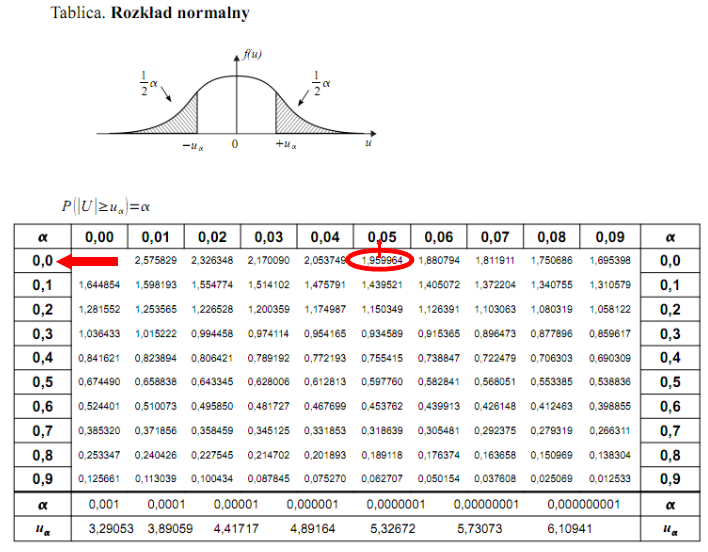
Dopiero teraz wracamy do odczytywania z tablic, jest to tzw. „zadanie od tyłu”, więc i z tablic czytamy od tyłu, a więc szukamy wartości najbliższej 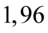 , ale w środku tablicy rozkładu normalnego. Wynikiem odczytywania są obrzeża tablicy, a więc inaczej niż zwykle.
, ale w środku tablicy rozkładu normalnego. Wynikiem odczytywania są obrzeża tablicy, a więc inaczej niż zwykle.
Najbliższą wartością 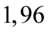 we wnętrzu tablicy stanowi
we wnętrzu tablicy stanowi 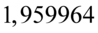 . Odczytując sumuje się wartości znajdujące się na obrzeżach tzn. z kolumny, która stanowi części dziesiętne i z wiersza, który traktujemy jako części setne. Sumujemy
. Odczytując sumuje się wartości znajdujące się na obrzeżach tzn. z kolumny, która stanowi części dziesiętne i z wiersza, który traktujemy jako części setne. Sumujemy 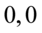 i
i 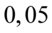 czyli
czyli 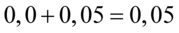 . Pamiętajmy, że jest to
. Pamiętajmy, że jest to 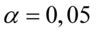 .
.
5. WYNIK I INTERPRETACJA.
Ostatecznie otrzymujemy współczynnik ufności: 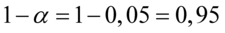 .
.
Interpretacja brzmi następująco:
Z ufnością 0,95 średni czas pisania jednej strony tekstu przez ogół maszynistek mieści się w przedziale od 5,804 min. do 6,196 min.
Zadanie pochodzi z: Statystyka zbiór zadań / Helena Kassyk-Rokicka. - Polskie Wydawnictwo Ekonomiczne - ISBN 83-208-1107-4