Badanie wydajności jednej z firm, przeprowadzone na podstawie 100-elementowej próby losowej prostej, dało następujące wyniki:
Jakiego zróżnicowania wydajności pracy należy spodziewać się w całej populacji pracowników przy współczynniku ufności 0,96? Zakładamy, że rozkład badanej cechy jest normalny.
1. JAK ROZPOZNAĆ ZADANIE DOTYCZĄCE ESTYMACJI PRZEDZIAŁOWEJ ?
Po przeczytaniu całego zadania zwracamy uwagę na zdanie:
Jakiego zróżnicowania wydajności pracy należy spodziewać się w całej populacji pracowników przy współczynniku ufności 0,96?
Co prawda nie użyto bezpośrednio zwrotu przedział ufności, ale musimy określić zróżnicowanie wydajności pracy dla całej populacji na podstawie wylosowanej próby, więc wypadałoby podać przedział ufności, bo tzw. estymacja punktowa (tzn. konkretna liczba, a nie przedział) daje wynik o prawdopodobieństwie praktycznie równym zero. Dodatkowo występuje tu zwrot: współczynnik ufności i w związku z tym na pewno jest to zadanie dotyczące estymacji przedziałowej.
2. ANALIZA I PRAWIDŁOWE WYPISANIE DANYCH.
Analizujemy zdanie po zdaniu.
Badanie wydajności jednej z firm, przeprowadzone na podstawie 100-elementowej próby losowej prostej, dało następujące wyniki:
Od razu uzyskujemy informację, że wylosowaliśmy próbę, a jej liczebność to
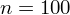 osób i od tego momentu będziemy stosować oznaczenia parametrów dla próby, chyba że zostanie wyraźnie określone, że będą to parametry dla populacji. Podano również wyniki z próby w tabeli. Jeżeli dysponujemy danymi dotyczącymi próby ujętymi w tabeli, to zawsze możemy policzyć średnią
osób i od tego momentu będziemy stosować oznaczenia parametrów dla próby, chyba że zostanie wyraźnie określone, że będą to parametry dla populacji. Podano również wyniki z próby w tabeli. Jeżeli dysponujemy danymi dotyczącymi próby ujętymi w tabeli, to zawsze możemy policzyć średnią
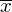 , wariancję
, wariancję
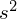 i odchylenie standardowe
i odchylenie standardowe
 (lub
(lub
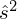 ,
,
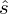 ). Nie liczmy jednak tych parametrów od razu, ponieważ dopiero etap wyboru formuły na estymację wskaże nam czego potrzebujemy. Po prostu chodzi o to, żeby nie liczyć na zapas np. odchylenia, bo może okazać się niepotrzebne w późniejszych obliczeniach.
). Nie liczmy jednak tych parametrów od razu, ponieważ dopiero etap wyboru formuły na estymację wskaże nam czego potrzebujemy. Po prostu chodzi o to, żeby nie liczyć na zapas np. odchylenia, bo może okazać się niepotrzebne w późniejszych obliczeniach.
Jakiego zróżnicowania wydajności pracy należy spodziewać się w całej populacji pracowników przy współczynniku ufności 0,96?
Podano też współczynnik ufności
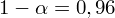 . Od razu wyznaczamy
. Od razu wyznaczamy
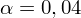 .
.
Zakładamy, że rozkład badanej cechy jest normalny.
W tym zdaniu występuje założenie normalności rozkładu wydajności pracy i to już odnosi się do populacji (wcześniej wspominałam w części teoretycznej, że próba jest z reguły za mała aby stwierdzić rozkład normalny). Nie mamy informacji na temat tego rozkładu, zatem możemy tylko zapisać
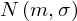 - rozkład normalny o nieznanej średniej
- rozkład normalny o nieznanej średniej
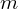 i nieznanym odchyleniu standardowym
i nieznanym odchyleniu standardowym
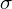 .
.
Podsumowując tworzymy przejrzystą tabelę z danymi:
|
POPULACJA
pracownicy pewnej firmy
|
PRÓBA
100 wybranych pracowników
|
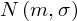 - rozkład normalny o nieznanej średniej
- rozkład normalny o nieznanej średniej
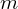 i nieznanym odchyleniu standardowym
i nieznanym odchyleniu standardowym
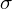
|
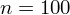 - dane tabelaryczne (można obliczyć średnią
- dane tabelaryczne (można obliczyć średnią
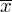 , wariancję
, wariancję
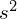 , odchylenie standardowe
, odchylenie standardowe
 )
)
|
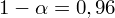 - współczynnik ufności,
- współczynnik ufności,
3. WYBÓR ODPOWIEDNIEGO WZORU.
Szukamy parametru, który należy oszacować przedziałem ufności i w ostatnim zdaniu wyłapujemy słowo:
Jakiego zróżnicowania wydajności pracy należy spodziewać się w całej populacji pracowników przy współczynniku ufności 0,96?
Wyrażenie
zróżnicowanie
nie wskazuje bezpośrednio na parametr, który należy oszacować przedziałem ufności, ale jeśli w zdaniu odnajdziemy takie słowo, to wiąże się ono albo z wariancją albo odchyleniem standardowym i to od nas zależy, który z nich wybierzemy (w końcu odchylenie standardowe to pierwiastek z wariancji). Także w tym zadaniu będziemy budować przedział ufności dla odchylenia standardowego
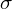 z populacji.
z populacji.
Spójrzmy w kartę wzorów. Dla odchylenia standardowego mamy do wyboru dwa modele. Teraz wracamy do danych i sprawdzamy, czy jest
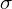 znana i jaka jest liczebność próby.
znana i jaka jest liczebność próby.
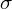 nie jest znana
, a liczebność próby
nie jest znana
, a liczebność próby
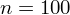 jest większa od 30
jest większa od 30
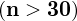 , zatem wybieramy
model II
.
, zatem wybieramy
model II
.

4. UZUPEŁNIANIE WYBRANEGO WZORU I OBLICZENIA.
Wracamy do danych z tabeli i uzupełniamy wzór
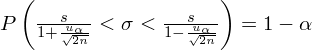 konkretnymi danymi.
konkretnymi danymi.
Jak widać do obliczenia końcówek przedziału ufności potrzebujemy odchylenia standardowego
 z próby. W związku z tym, zanim zajmiemy się uzupełnianiem właściwego wzoru, należy obliczyć (na razie) nieznany parametr. Liczenie odchylenia standardowego jest zagadnieniem ze statystyki opisowej. Dysponujemy danymi tabelarycznymi, gdzie warianty cechy (wiek w latach) są w formie przedziałów tzn. od jednej wartości do drugiej wartości. Taki szereg określa się szeregiem rozdzielczym przedziałowym. Przeredagujmy zatem tabelę z zadania właśnie na tą postać szeregu.
z próby. W związku z tym, zanim zajmiemy się uzupełnianiem właściwego wzoru, należy obliczyć (na razie) nieznany parametr. Liczenie odchylenia standardowego jest zagadnieniem ze statystyki opisowej. Dysponujemy danymi tabelarycznymi, gdzie warianty cechy (wiek w latach) są w formie przedziałów tzn. od jednej wartości do drugiej wartości. Taki szereg określa się szeregiem rozdzielczym przedziałowym. Przeredagujmy zatem tabelę z zadania właśnie na tą postać szeregu.
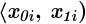 - warianty obserwacji (wydajność w sztukach)
- warianty obserwacji (wydajność w sztukach)
|
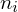 - liczebności poszczególnych przedziałów klasowych (liczba osób)
- liczebności poszczególnych przedziałów klasowych (liczba osób)
|
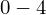
|
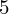
|
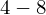
|
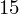
|
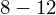
|
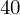
|
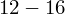
|
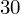
|
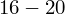
|
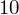
|
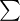 (suma)
(suma)
|
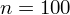
|
W przypadku szeregu rozdzielczego przedziałowego nie ma możliwości pomyłki do tego, co jest wariantem cechy, a co liczebnością
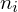 , ponieważ nie zdarza się, aby
, ponieważ nie zdarza się, aby
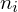 było zapisane w formie przedziałów. Symbol
było zapisane w formie przedziałów. Symbol
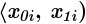 to po prostu ogólny zapis przedziału lewostronnie domkniętego i prawostronnie otwartego (chyba najczęściej używany – chociaż zależy od preferencji prowadzącego). Należy pilnować, aby końcówka każdego przedziału była początkiem następnego. W tabeli z zadania mamy właśnie przedstawioną sytuację
to po prostu ogólny zapis przedziału lewostronnie domkniętego i prawostronnie otwartego (chyba najczęściej używany – chociaż zależy od preferencji prowadzącego). Należy pilnować, aby końcówka każdego przedziału była początkiem następnego. W tabeli z zadania mamy właśnie przedstawioną sytuację
 ,
,
 (kończymy przedział na 4, następny również zaczynamy od 4), itd. w związku z tym nie musimy nic zmieniać, zachowana jest ciągłość.
(kończymy przedział na 4, następny również zaczynamy od 4), itd. w związku z tym nie musimy nic zmieniać, zachowana jest ciągłość.
Aby otrzymać odchylenie standardowe i tak musimy obliczyć wariancję, bo odchylenie jest pierwiastkiem kwadratowym z wariacji. Wzór na wariancję z danych szeregu przedziałowego wygląda następująco:
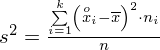 . Jest też alternatywa
. Jest też alternatywa
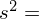
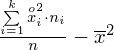 , ale będziemy używać pierwszej wersji. Okazuje się, że do policzenia wariancji i tak niezbędna jest średnia.
, ale będziemy używać pierwszej wersji. Okazuje się, że do policzenia wariancji i tak niezbędna jest średnia.
W szeregu przedziałowym średnią liczymy ze wzoru
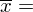
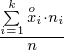 . Na początku wyjaśnijmy symbol
. Na początku wyjaśnijmy symbol
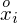 . Oznacza on środek każdego z podanych przedziałów, a obliczany jest na podstawie formuły
. Oznacza on środek każdego z podanych przedziałów, a obliczany jest na podstawie formuły
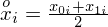 . Upraszczając, należy zsumować początek i koniec każdego przedziału i wynik podzielić na dwa. Wracamy do wzoru na średnią. Znak
. Upraszczając, należy zsumować początek i koniec każdego przedziału i wynik podzielić na dwa. Wracamy do wzoru na średnią. Znak
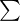 oznacza sumę. Pod tym symbolem znajduje się zapis
oznacza sumę. Pod tym symbolem znajduje się zapis
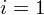 , a nad nim
, a nad nim
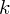 ,
,
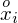 to środki kolejnych przedziałów , a
to środki kolejnych przedziałów , a
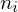 liczebności dla kolejnych przedziałów. Wszystko razem oznacza, że będziemy sumować kolejne iloczyny
liczebności dla kolejnych przedziałów. Wszystko razem oznacza, że będziemy sumować kolejne iloczyny
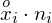 , gdzie
, gdzie
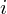 będzie rosło od
będzie rosło od
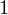 aż do wartości
aż do wartości
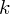 , czyli
, czyli
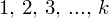 , a więc ogólnie:
, a więc ogólnie:
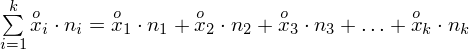
W naszym przypadku
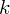 znad znaku sumy oznacza liczbę przedziałów klasowych (ilość wierszy w tabeli z danymi). Tak więc średnia będzie miała uproszczony wzór:
znad znaku sumy oznacza liczbę przedziałów klasowych (ilość wierszy w tabeli z danymi). Tak więc średnia będzie miała uproszczony wzór:
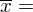
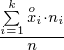 =
=
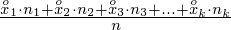
Czym jest
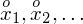 ,
,
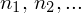 oraz
oraz
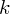 ? Wszystko to zostanie pokazane dokładnie w tabeli. Obliczmy w niej również środki poszczególnych przedziałów.
? Wszystko to zostanie pokazane dokładnie w tabeli. Obliczmy w niej również środki poszczególnych przedziałów.
|
Numer klasy
|
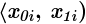 - warianty obserwacji (wiek)
- warianty obserwacji (wiek)
|
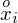 - środki przedziałów
- środki przedziałów
|
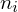 - liczebności poszczególnych przedziałów klasowych (liczba osób)
- liczebności poszczególnych przedziałów klasowych (liczba osób)
|
|
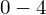
|
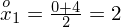
|
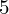
|
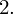
|
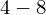
|
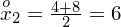
|
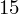
|
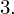
|
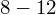
|
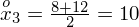
|
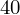
|
|
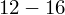
|
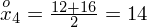
|
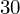
|
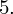
|
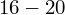
|
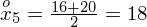
|
|
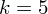
|
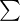 (suma)
(suma)
|
|
|
Uzupełniając wzór średniej dla
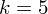 otrzymujemy:
otrzymujemy:
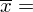
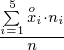 =
=
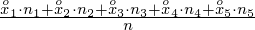 i oczywiście możemy uzupełnić go danymi z tabeli, ale proponuję nadal korzystać z tabeli i wykonywać w niej obliczenia. Po pierwsze jest bardziej klarowna, po drugie ułamek powstały po rozpisaniu wzoru może okazać się dłuższy niż w tym konkretnym zadaniu i łatwo tu o pomyłkę. W tabelce powoli budujemy wzór na średnią z szeregu przedziałowego, a jej nagłówki zawsze wyglądają tak samo. Każdą wartość
i oczywiście możemy uzupełnić go danymi z tabeli, ale proponuję nadal korzystać z tabeli i wykonywać w niej obliczenia. Po pierwsze jest bardziej klarowna, po drugie ułamek powstały po rozpisaniu wzoru może okazać się dłuższy niż w tym konkretnym zadaniu i łatwo tu o pomyłkę. W tabelce powoli budujemy wzór na średnią z szeregu przedziałowego, a jej nagłówki zawsze wyglądają tak samo. Każdą wartość
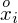 mnożymy przez odpowiadającą jej wartość
mnożymy przez odpowiadającą jej wartość
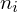 , a następnie sumujemy powstałe iloczyny. Przecięcie wiersza z symbolem
, a następnie sumujemy powstałe iloczyny. Przecięcie wiersza z symbolem
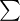 i kolumny
i kolumny
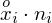 daje kompletny licznik wzoru na średnią.
daje kompletny licznik wzoru na średnią.
|
Numer klasy
|
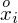 - środki przedziałów
- środki przedziałów
|
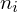 - liczebności poszczególnych przedziałów klasowych
- liczebności poszczególnych przedziałów klasowych
|
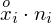
|
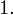
|
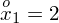
|
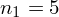
|
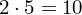
|
|
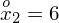
|
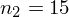
|
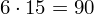
|
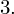
|
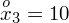
|
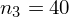
|
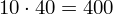
|
|
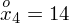
|
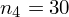
|
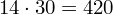
|
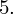
|
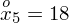
|
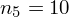
|
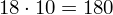
|
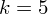
|
|
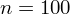
|
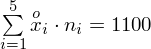
|
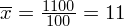
Dysponujemy wartością średniej, zatem możemy wrócić do obliczania wariancji. Rozpiszemy wzór analogicznie jak w przypadku średniej. Najpierw ogólnie:
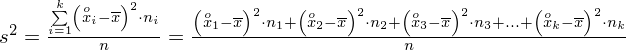
i dla
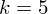 :
:
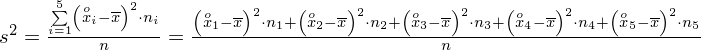
Tu też można podstawiać dane z tabeli, ale ponownie proponuję trzymać się obliczeń tabelarycznych. Można kontynuować poprzednią tabelę dopisując kolejne kolumny. Znowu krok po kroku będziemy tworzyć licznik ze wzoru. Dopisana pierwsza kolumna - od każdego środka przedziału
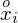 odejmujemy wcześniej wyliczoną średnią
odejmujemy wcześniej wyliczoną średnią
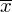 , druga kolumna to podniesienie wyników z poprzedniej do kwadratu. Ostatnia to wymnożenie wyników z drugiej przez odpowiadające im wartości
, druga kolumna to podniesienie wyników z poprzedniej do kwadratu. Ostatnia to wymnożenie wyników z drugiej przez odpowiadające im wartości
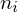 i dopiero ona jest sumowana (przecięcie wiersza z symbolem
i dopiero ona jest sumowana (przecięcie wiersza z symbolem
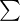 i
i
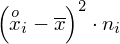 daje kompletny licznik wzoru na wariancję).
daje kompletny licznik wzoru na wariancję).
|
Numer klasy
|
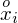 - środki przedziałów
- środki przedziałów
|
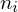 - liczebności poszczególnych przedziałów klasowych
- liczebności poszczególnych przedziałów klasowych
|
|
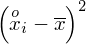
|
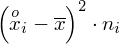
|
|
|
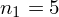
|
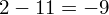
|
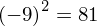
|
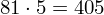
|
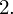
|
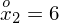
|
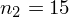
|
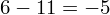
|
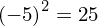
|
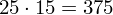
|
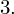
|
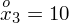
|
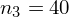
|
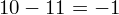
|
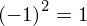
|
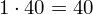
|
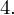
|
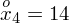
|
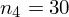
|
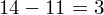
|
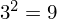
|
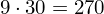
|
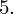
|
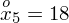
|
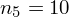
|
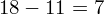
|
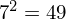
|
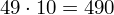
|
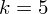
|
|
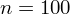
|
|
|
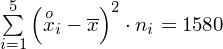
|
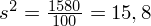
Odchylenie standardowe
 to pierwiastek z wariancji
to pierwiastek z wariancji
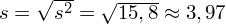 .
.
Wracamy do danych z tabeli i wreszcie uzupełniamy wzór
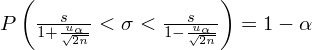 konkretnymi danymi.
konkretnymi danymi.
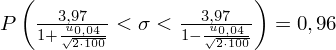
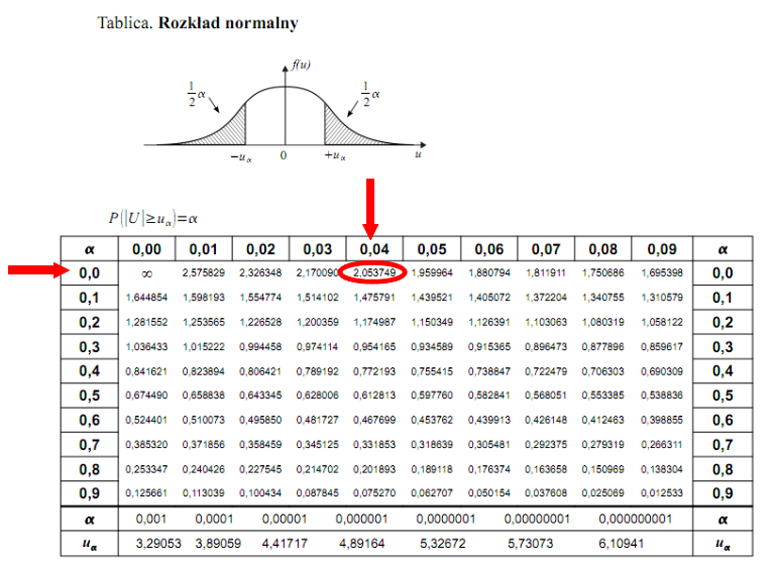
Teraz należy odczytać odpowiednią statystykę z tablic. W formule znajduje się literka
u
, zatem skorzystamy z tablic rozkładu normalnego (link). Zapis
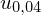 oznacza konieczność odnalezienia statystyki dla
oznacza konieczność odnalezienia statystyki dla
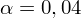 . Czytanie z tablic rozkładu normalnego nie jest trudne. Sumuje się wartości znajdujące się na obrzeżach tzn. z kolumny, która stanowi części dziesiętne i z wiersza, który traktujemy jako części setne. W przypadku
. Czytanie z tablic rozkładu normalnego nie jest trudne. Sumuje się wartości znajdujące się na obrzeżach tzn. z kolumny, która stanowi części dziesiętne i z wiersza, który traktujemy jako części setne. W przypadku
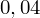 sumujemy
sumujemy
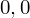 i
i
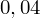 czyli
czyli
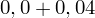 .
.
Wracamy do obliczeń i podstawiamy
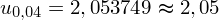 (zaokrąglanie to indywidualna sprawa wynikająca najczęściej z preferencji prowadzącego):
(zaokrąglanie to indywidualna sprawa wynikająca najczęściej z preferencji prowadzącego):
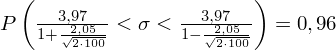
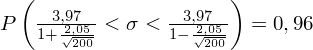
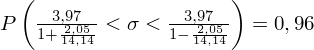
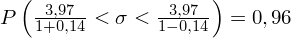
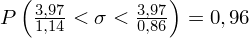
5. WYNIK I INTERPRETACJA.
Ostatecznie otrzymujemy:
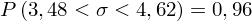
Interpretacja brzmi następująco: Z ufnością 0,96 nieznane odchylenie standardowe wydajności pracy w całej populacji pracowników mieści się w przedziale od 3,48 do 4,62 sztuk.
Mieczysław Sobczyk - Statystyka. Aspekty praktyczne i teoretyczne, Wydawnictwo: Uniwersytet Marii Curie - Skłodowskiej 2006,ISBN: 83-227-2423-3, str. 118